오픈 이슈 갤러리 같이 보고 싶은 유머 글이나 이미지를 올려보세요!
URL 입력
-
계층
폐지 줍줍
[13]
-
유머
슈카가 말하는 미국/한국 기업 상속
[49]
-
연예
오빠, 이거 유료서비스에요.
[24]
-
계층
결혼 출산율 높이는 방법
[19]
-
게임
한국 게임계 4대 성인들
[71]
-
계층
간호사들이 입 모아 천사라고 부르는 사람
[41]
-
계층
폐지 줍줍
[7]
-
연예
강한나 배우 새로운 프로필 사진
[18]
-
유머
페미니스트를 가장 정확하게 설명하신 분
[13]
-
계층
ㅎㅂ)요즘 게시물을 퍼오기도 힘드네요
[19]
이미지 업로드중입니다
(1/5)
URL 입력
ㅇㅇㄱ 지금 뜨는 글
|
2019-10-22 10:23
조회: 9,215
추천: 6
수치예보2 - 자료동화수치모델 이야기1 - http://www.inven.co.kr/board/webzine/2097/1292531?my=post&iskin=webzine
여러분이 저번 글을 읽고나서 기억하셔야할 건 몇 가지 없습니다. 1. 수치예보모델에는 매우 복잡한 식들이 들어간다. 그리고 그건 인간에게도 컴퓨터에게도 어렵다. 2. 그 중에는  아주 중요한 식이 있는데 정말정말정말정말 중요하다. 3. 유럽 vs 미국 ---------------------------------------------------------------------------------------------------------- 이제 이번 이야기를 시작해보겠습니다. 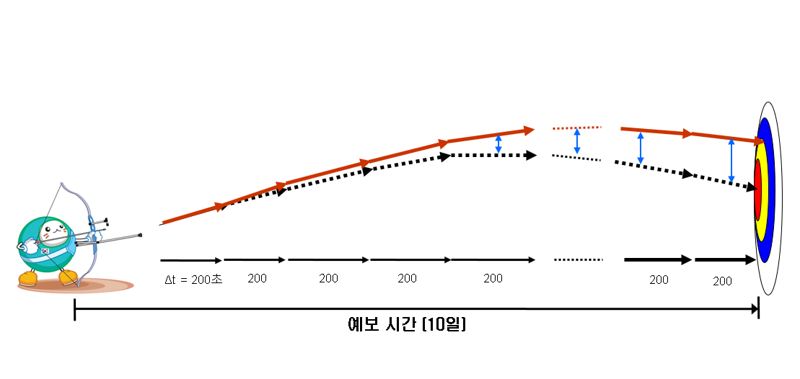 일기예보는 결국 틀릴 수 밖에 없는 운명을 가지고 있고 수치예보 또한 '물리학적으로 반드시' 틀릴 수 밖에 없는 운명을 가지고 있습니다. 왜냐하면 1. 관측값과 예측값 사이의 오차 2. 관측과정에서 생기는 관측오차. 크게 봤을 때는 이 두 가지의 오차요인 때문에 수치예보는 반드시 현실과 차이가 존재하며 시간이 지날수록 그 오차는 커집니다. 아까 제가 예보는 물리학적으로 반드시 틀릴 수 밖에 없다고 했었죠? 이 말은 위에 적어둔 이야기를 식으로 표현할 수 있다는 소리인데요. 그 식은 다름아닌 바로 이겁니다. 위의 식에서 B는 배경오차(정확히는 배경오차 공분산)을 의미하고 O는 관측오차(관측오차 공분산)를 의미합니다. 그리고 우변 끝에 있는 건 숫자 0 입니다. 이 식을 어떻게 어떻게 잘 풀어보면 오차를 나타내는 항들은 시간이 경과하면서 점점 커지게 되거든요. 그리고 오차를 다루는 변수들이 들어가있는 이 식은 오차델 이야기1 - http://www.inven.co.kr/board/webzine/2097/1292531?my=post&iskin=webzine 여러분이 저번 글을 읽고나서 기억하셔야할 건 몇 가지 없습니다. 1. 수치예보모델에는 매우 복잡한 식들이 들어간다. 그리고 그건 인간에게도 컴퓨터에게도 어렵다. 2. 그 중에는  아주 중요한 식이 있는데 정말정말정말정말 중요하다. 3. 유럽 vs 미국 ---------------------------------------------------------------------------------------------------------- 이제 이번 이야기를 시작해보겠습니다.  일기예보는 결국 틀릴 수 밖에 없는 운명을 가지고 있고 수치예보 또한 '물리학적으로 반드시' 틀릴 수 밖에 없는 운명을 가지고 있습니다. 왜냐하면 1. 관측값과 예측값 사이의 오차 2. 관측과정에서 생기는 관측오차. 크게 봤을 때는 이 두 가지의 오차요인 때문에 수치예보는 반드시 현실과 차이가 존재하며 시간이 지날수록 그 오차는 커집니다. 아까 제가 예보는 물리학적으로 반드시 틀릴 수 밖에 없다고 했었죠? 이 말은 위에 적어둔 이야기를 식으로 표현할 수 있다는 소리인데요. 그 식은 다름아닌  바로 이겁니다. 위의 식에서 B는 배경오차(정확히는 배경오차 공분산)을 의미하고 O는 관측오차(관측오차 공분산)를 의미합니다. 그리고 우변 끝에 있는 건 숫자 0 입니다. 이 식을 어떻게 어떻게 잘 풀어보면 오차를 나타내는 항들은 시간이 경과하면서 점점 커지게 되거든요. 그리고 오차를 표현하는 항들이 식에 들어가있는 이유는 실제 현실과 수치모델 간에 존재하는 오차들을 정량적으로 파악하기 위해서이고, 더 나아가서 이 방정식의 목적은 모델이 가지고 있는 오차를 현실에 가깝게 보정하는 것이 되는거죠. 전문용어로는 '자료동화'라고 부릅니다. 영어로는 'assimilation' 이라고 부르는데 어렵게 생각하실 것 없습니다.  스타크래프트에서 프로토스 종족의 베스핀가스 채취건물이름이 assimilator(융화소)잖아요? 가스를 융화시킨다고 표현하는데 이는 가스를 사용할 수 있게 변화시키기 때문에 그런 이름을 붙였다고 하더군요. 자료동화(assimilation) 또한 마찬가지입니다.  컴퓨터가 수치모델로 예보를 하기위해서는 반드시 자료동화라는 과정을 거쳐야만 하거든요. 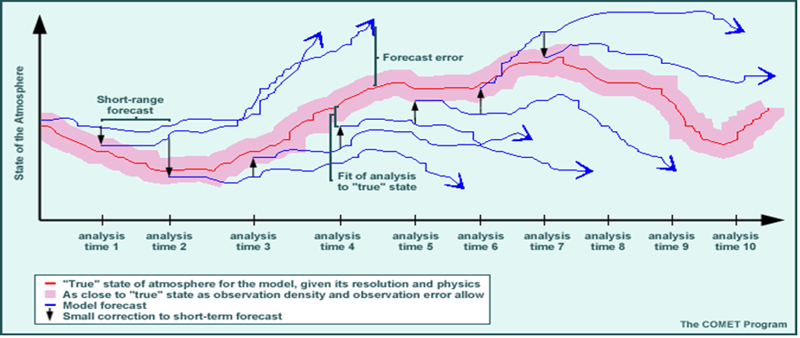 위 그림에서처럼 그냥 놔두면 파란색 화살표처럼 안드로메다로 가버리는 게 수치예보모델이기 때문에 반드시 사람이 개입해서 보정을 해줘야 합니다. -중간정리 1. 수치모델은 시작부터 오차를 내포하고 있고 이 오차는 절대로 감소하지 않고 증가한다.(누가 예보해도 마찬가지다.) 2. 때문에 매일 주기적으로 자료동화 라는 전처리 과정을 시행한다. 3. 자료동화는 관측자료를 이용해 모델이 가지는 오차를 주기적으로 보정하는 행위다. 4. 기상관측은 모델이 현실과 동떨어지게 나아가는 것을 바로 잡아준다. 5. 전 시간 모델 예측결과를 관측자료와 비교하여 '가장 정확도가 높은' 모델 입력 초기장을 생성한다. 그리고 1~5를 매일 수차례 반복한다. 여기서 5번을 주목해주십쇼. '관측자료와 비교하여 가장 정확도가 높은 초기형태를 생성한다'는 부분말입니다. 이거 외부인(특히 국회의원)의 시선에서 보면 사실 웃기는 짓입니다. 답이 나왔는데 답을 안보고 답에 가까운 풀이로 시작한다는 소리잖아요? 하지만 그래야 합니다. 그 이유는 뒤에서 설명드리기로 하고 숫자를 좋아하는 변태들답게 물리학자와 수학자들은 이런 자료동화의 기본 개념마저도 수식으로 정리해놨습니다. A = F + HT W ( O – HF ) 모델입력장 = 전시간예보장 + 가중치 X (관측자료-전시간예보장) 위에 있는 저 가중치 W에 의해서 컴퓨터에 입력할 예보장에 얼마나 현실을 반영시킬지가 결정되는데 뭐 잊어먹으셔도 무방합니다. 아무튼 이 모든 과정을 그림으로 정리해보면 간단합니다. 그리고 이 간단해 보이는 자료동화 처리를 할 수 있는 나라는 우리나라를 포함한 8개국 뿐입니다.  하지만 왜? 현실에 제일 가까운 관측결과를 그대로 넣지 않고 참조해서 반영만 하는 걸까요?????  모 타이쿤 게임에서처럼 집게로 잡아내서 옮긴다든가 하면 간단할텐데 말이죠. 이유는 간단합니다. 그러면 컴퓨터가 퍼지거나 모델이 터지거든요. 자세한 설명을 하기 전에 간단한 컴퓨터 시뮬레이션을 하나 보실까요? 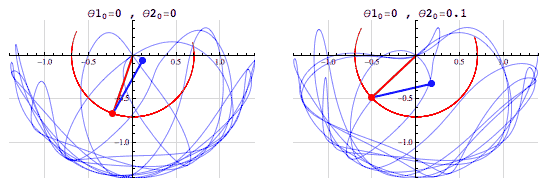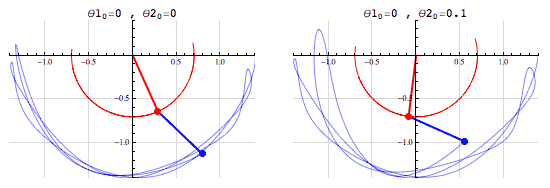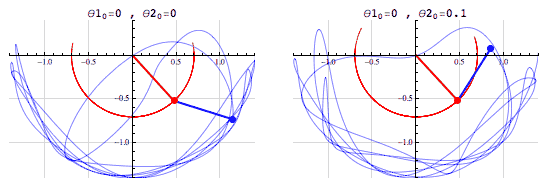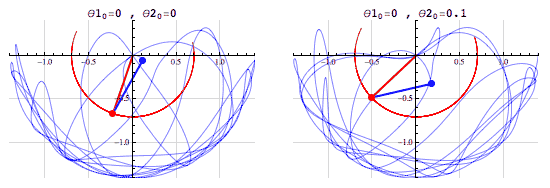 이 것은 진자 끝에 다른 진자를 하나 더 달아놓은 이중진자(double pendulum)에 대한 시뮬레이션입니다. 하나는 (0, 0) 다른 하나는 (0, 0.1) 에서 시작하는 점 외에는 모든 조건이 동일합니다. 마지막에 두 진자가 그린 궤적만 놓고봤을 때는 얼추 비슷해보이지만 그 운동과정은 매우 다르죠. 예전에 유행했던 나비효과라는 영화 기억나시나요?  이 영화의 모티브이자 제목이기도 한 나비효과(혼돈이론)의 대표적인 사례가 바로 이중진자입니다. (물론 영화내용은 원래의 나비효과와는 전혀 관계가 없었지만요.) 이제 다시 수치예보 모델을 떠올려 봅시다. 수치예보 모델은 그야말로 혼돈 그 자체인 지구의 대기흐름을 구현해놓은 시뮬레이션이고 대기흐름은 그야말로 혼돈 그 자체이기 때문에 어떤 수치모델이라고 해도 그 상태는 매우 불안정한 상태입니다. 이해를 돕기위해 예를 들어서 설명해보겠습니다. 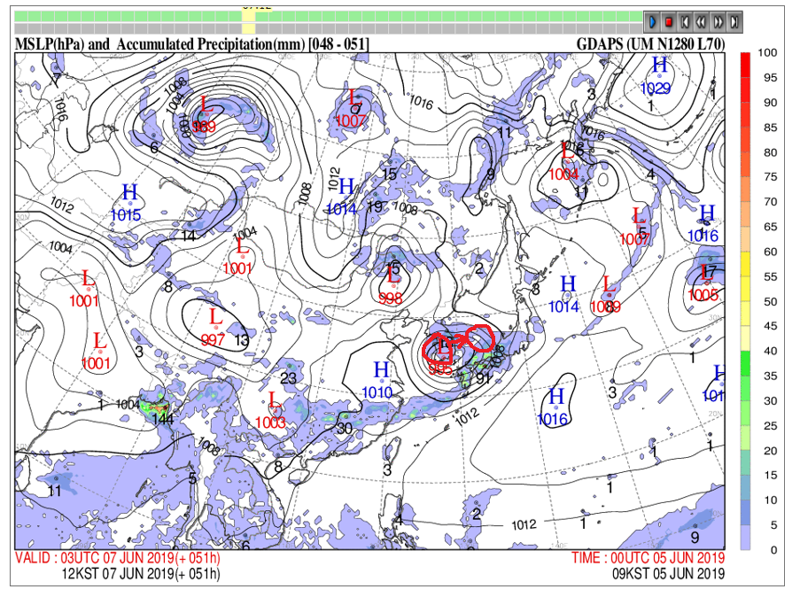 위 그림은 수치모델을 통해 얻어내는 예상일기도입니다. 만약 이 그림과 달리 실제 현실에서는 저기압이 부산을 지나갔다고 쳐봅시다. 그리고 그 관측결과에 맞춰서 저기압을 부산으로 옮길 경우 그림 상에서는 몇cm도 안되는 짧은 거리지만 실제로는 200km가 넘는 거리를 이동한 셈이 됩니다. 그리고 기존에 저기압이 있던 자리에는 공백이 생기게 되구요. 그리고 서쪽에 있는 기압들이 그 거리를 메꾼다고 쳐보죠. 보통 이런 경우 뒤로 갈수록 메꿔야할 거리는 점점 더 커지겠죠? 슈퍼컴퓨터는 이 모든 영향을 계산해서 전 지구의 기압계를 새로 그려내야 합니다. 이 과정에서 당연하게도 수치모델과 슈퍼컴퓨터 모두 엄청난 부하를 받게 됩니다. 그리고 그 과정에서 무리한 이동이 나비효과를 일으켜서 더 큰 오차값을 가져오거나 롤........백을 해야할 상황이 올수도 있겠죠.(근데 롤백이 가능할지도 의문입니다.) 말이 좋아 롤백이지, 폐기수순을 밟는다는 소리입니다. 위의 기술적인 부분은 저도 귀동냥으로 들은 이야기라 일단 써보기는 했는데 정확한 이야기는 밤에 출근해서 물어봐야겠네요. 최종정리. 1. 수치모델은 시작부터 오차를 내포하고 있고 이 오차는 절대로 감소하지 않고 증가한다.(누가 예보해도 마찬가지다.) 2. 때문에 매일 주기적으로 자료동화 라는 전처리 과정을 시행한다. 3. 자료동화는 현실을 그대로 카피하는 게 아니라 현실에 가깝게 시뮬레이션을 '보정'하는 것이다. 4. 수치예보 모델은 아슬아슬한 균형을 맞춰가고 있기 때문에 함부로 조작할 수는 없다. 앞으로 수치예보에 대한두편 정도 더 올릴 거 같은데요. 다음 글은 유럽, 미국, 한국의 자료동화 기법소개 마지막 글은 예보관의 무덤이자 수치예보 모델의 성능을 극한까지 시험하는 태풍보거싱(모조태풍) 이야기를 할 것 같습니다. 읽어주셔서 감사합니다. p.s 제 능력으로는 더 이상 쉽게 쓰기는 어렵네요ㅠ 사실 이 글 하나 쓰는데만 해도 정말 오래 걸립니다 ㅠ 퇴근해서 집에 오자마자 썼는데 1시간 50분 정도 걸리네요. 이런 설명들을 넣었다 뺏다 하느라고...  견본이지만 빗방울에 대한 소스코드는 대충 이런식이라는군요. 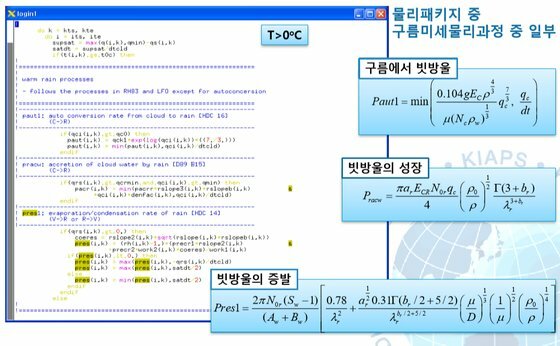 |
 고전역학
고전역학 