오늘날 온라인 게임에는 수많은 유저가 접속해 어마어마한 양의 데이터를 생산해낸다. 얼핏 보기에 화려하기만 한 외형이지만, 그 속에는 다양한 정보값들이 넘실댄다. 당연하게도 그 정보의 바다에는 ‘틀린 정보’들이 생기고는 한다. 게이머들이 흔히 말하는 버그나 어뷰징들이 대표적인 원인이다.
■ 게임 재화 이상 탐지의 필요성

엔씨소프트 인텔리전스랩스 소속 엄헤민 연구원은 연단에 올라 게임 내 데이터 분석의 중요성과 방법론에 대해 논했다.
게임 재화 이상 탐지는 어째서 필요할까? 엄혜민 연구원은 이 질문에 대해 게임 경제가 현실과 유사하기 때문이라고 답했다. 리니지의 아데나처럼 게임 속에는 재화가 있기 마련이고, 이는 유저들의 사냥활동 등을 통해 생산된다. 그리고 유저들은 무기를 구매하며 재화를 소비하기도 하고, 서로 거래를 하면서 시장을 형성하기도 한다.
그녀는 만약 재화가 소비 없이 늘어나기만 하면 게임 내에도 인플레이션이 발생한다고 경고했다. 현실과 마찬가지로 재화가치가 큰 폭으로 하락하고, 기존 유저와 신규 유저간의 빈부격차가 심화되는 등 다양한 경제적 문제가 발생하게 된다고 말했다.

엄혜민 연구원은 이러한 사태를 방지하기 위해 운영 측은 게임 운영을 통해 재화의 획득량과 소모량을 적절하게 유지해야 한다고 주장했다. 만약 게임 내 버그나 어뷰징으로 재화가 급격하게 증가하게 되고, 이를 막지 못할 경우 서비스에 치명적인 영향을 줄 수 있다고 덧붙였다. 실제로 소위 ‘복사 버그’ 등을 잡지 못해 롤백까지 일어난 사례가 있었다고 언급했다.
재화 이상 현상을 조기에 감지하는 게 중요하다고 언급한 그녀는 운영진들이 일일이 지표를 모니터링하는 게 아무래도 비효율적이라 말했다. 특히, 이렇게 인력을 투자했는데도 사고가 터지게 되면 그 타격은 더욱 크게 돌아올 것이라며 재화 이상 탐지 시스템의 자동화가 필요하다고 강조했다.
■ 이상 데이터란?
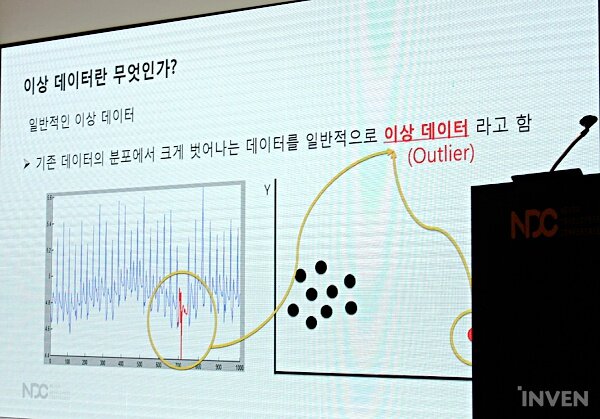
‘이상 데이터(outlier)’란 기존의 데이터 분포에서 크게 벗어나는 데이터를 뜻한다. 가장 기본적인 이상 데이터 탐지 방법은 평균과 분산을 이용하게 된다. 전체 데이터의 평균과 표준편차를 구한 뒤 해당 데이터가 평균으로부터 얼마나 벗어나 있는지를 대조하여 찾는 방법이다.
엄혜민 연구원은 평균과 표준편차만으로는 이상 데이터를 완벽히 잡을 수 없다고 밝혔다. 예를 들어 데이터가 상승 혹은 하락 추세인 경우, 기존 전체 평균값만으로는 이상 데이터를 탐지할 수 없다. 이 경우 오히려 정상 데이터가 이상 데이터로 탐지될 수도 있다. 그녀는 과거 데이터 분포만 참고하게 되면 시간이 갈수록 잘 못 탐지되는 경향이 있다며 새로운 접근방식을 가져야 한다고 언급했다.
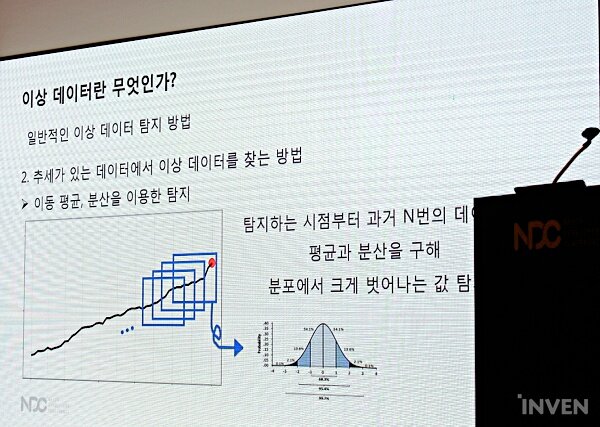
앞서 언급한 특정 추세가 보이는 데이터의 경우, ‘이동평균’과 ‘분산’을 이용해 탐지하는 게 용이하다. 탐지하는 시점부터 과거 N번의 데이터를 평균과 분산을 통해 분포에서 벗어나는 값을 추산하는 방식이다.
보다 복잡한 경우도 있다. 데이터가 주기성을 띌 경우, 또 다른 접근법을 고민해야 한다. 상승과 하락폭이 분명한 주기성 데이터는 ‘시계열 분석'을 이용해 접근해야 한다. ‘시계열 분석’은 ‘계절성’, ‘장기적 패턴’, 그리고 그 외 요소인 ‘리메인더(나머지 값)’로 이루어져 있다. 리메인더의 평균과 표준편차를 구한 뒤 해당 패턴과 전체 데이터를 비교해 벗어나는 지점의 값을 분석하는 방식으로 이상 데이터를 탐지할 수 있다.
■ 이상 데이터 탐지 방법
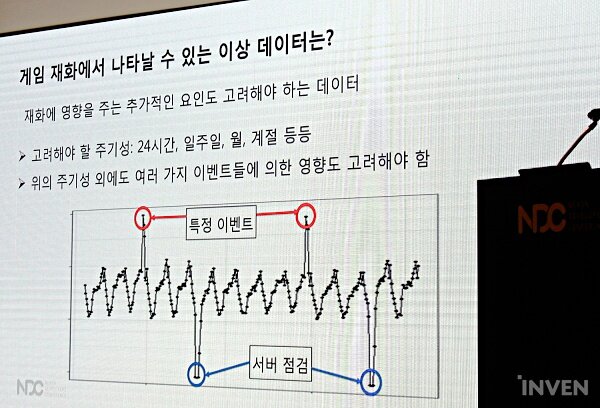
그렇다면 게임 내에서는 어떤 이상 데이터가 발생하며 어떻게 탐지할 수 있을까? 엄혜민 연구원은 게임 내에는 의외의 변수들이 존재한다고 밝혔다. 그녀는 기본적으로 시간에 따른 변동폭을 고려해야 한다고 주장했다. 예를 들어 유저들의 접속이 뜸해지는 새벽 시간의 경우, 재화 증감폭은 작아지는 데 반해 어뷰징은 쉽게 일어난다. 이러한 어뷰징을 이용한 재화의 증가량을 고려하지 않을 경우, 유저 활동량이 늘어난 저녁 시간대의 일반적인 값과 비슷하게 보일 우려가 있다. 그녀는 이러한 요소를 놓치지 않기 위해 시간대에 따른 ‘주기성’을 반드시 고려해야 한다고 말했다.
하지만 주기성 역시 다양하게 변화될 수 있다. 몇 월 몇 주인지, 무슨 계절인지에 따라서도 주기성은 변화한다. 또한, ‘특정 이벤트’나 ‘서버 점검’ 등의 요소 역시 게임 특유의 변인 중 하나다.
이에 엄혜민 연구원은 이상 데이터를 찾기 위해서는 무엇보다도 ‘정상 상태’를 정확히 정의하는 게 중요하다고 강조했다.

그녀는 이러한 정상상태를 정의하기 위해 재화 증가량을 예측하는 회귀 모델을 만들어 적용했다고 밝혔다. 회귀 모델이란 어떤 자료에 대해서 그 값에 영향을 주는 조건을 고려하여 구한 평균값이다. 이 모델은 주기성 같은 다양한 변인들을 쉽게 변수화해 사용할 수 있고, 매 변인들의 영향력 정도 역시 쉽게 알아낼 수 있다는 강점이 있다.
회귀 모델은 기본적으로 y=a+bx라는 공식으로 표현되며, 이 때 y는 결과값, x는 변인을 의미한다. a는 x를 통제했을 때 구할 수 있는 평균적인 y값을 의미하고, b는 x가 y값에 미치는 영향의 정도를 보여주는 값으로 ‘회귀 계수’라 불린다. 엄혜민 연구원은 a와 b를 통해 이벤트나 주기성이 재화 증감량에 미치는 영향의 정도를 알아낼 수도 있고, 전체적인 재화 증가량 역시 산출해낼 수 있다고 언급했다.
아울러 그녀는 회귀 모델의 올바른 사용을 위해 ‘데이터 탐색'이 먼저 이루어져야 한다고 밝혔다. "전체적인 증감 추이, 시간대와 요일에 따른 변동, 그리고 특정 이벤트나 아이템 판매로 인한 변화 등을 살펴봐야 한다”며, “나중에 회귀 모델의 설명 변수로 사용할 수 있다”고 언급했다.
■ 1차 탐지와 2차 탐지

이상 데이터 탐지는 기본적으로 1차와 2차로 나뉜다. 1차 이상 탐지 때는 회귀모델을 이용해 매시간별 재화 증가량을 예측하고, 해당 값에 대한 상하한선을 구해 시간별 증감량을 대조하게 된다. 만약 실제값이 예측값의 상하한선을 초과하는 경우 ‘이상 데이터’로 탐지하게 된다.
하지만 엄혜민 연구원은 정말 의외의 변인이 발생해 데이터가 어긋나는 경우가 있다고 밝혔다. 예를 들어, 유저가 창고에 모아두었던 아이템을 상점에 한 번에 판매할 경우 재화가 폭발적으로 증가할 수도 있다. 이는 버그나 어뷰징이 분명 아니지만, 예측값을 넘어서기 때문에 이상 데이터로 탐지될 가능성이 있다는 뜻이었다. 그녀는 이런 예상외의 사태에 대처하기 위해 ‘특정 시간 동안 n번 이상 발생할 경우 탐지한다’는 추가 룰(rule)을 적용했다.

2차 과정에서는 1차 과정에서 미처 탐지하지 못한 난해한 경우를 추가로 다루게 된다. 미미한 수준의 버그나 어뷰징이 발생할 경우, 이상 데이터가 존재해도 예측값의 상하한선을 넘지 않아 발견되지 않을 수 있다. 이러한 사태를 방지하기 위해, 2차 과정에서는 ‘잔차’를 이용해 보다 정밀한 탐지를 실시한다.
잔차는 예측값과 실제값의 차이를 뜻하며, 정상적으로 구할 경우 0을 기준으로 랜덤하게 분포하는 형태를 보인다. 만약 이상 데이터가 발생할 경우 잔차는 한쪽으로 쏠린 형태를 띄게 되는데, 이 잔차의 누적치를 지속적으로 모니터링하여 일정 규모 이상이 될 경우 이상 데이터로 탐지하게 된다.

엄혜민 연구원은 이러한 회귀 모델 분석 방식을 보다 편리하게 이용할 수 있는 탐지 프로세스를 공개했다. 해당 프로세스를 살펴보면, 먼저 기초 데이터를 사전 분석한 뒤 회귀 모델을 구축하고 예측을 실시하게 된다. 만약 탐지된 이상 데이터가 원인 분석 결과 문제가 없는 것으로 판단되는 경우가 반복된다면 회귀 모델 자체를 다시 설계할 것인지 판단해야 한다.
아울러 그녀는 운영 측이 해당 데이터를 보다 쉽게 보고 판단할 수 있도록 모니터링 페이지를 별도 구축해 운영 중이라고 밝혔다. 해당 모니터링 페이지는 어떤 이유로 예측 상한선을 넘어섰는지, 해당 값이 최근 동일 시간대에 비해 얼마나 높은 값인지를 요약해 보여주는 방식이라고 덧붙였다.

