주제: Game Data analysis with Deep Learning
강연자 : 김승원 - 크래프톤 / KRAFTON
발표분야 : 프로그래밍
권장 대상 : Data analyst
난이도 : 기본적인 사전지식 필요
[강연 주제] Game data (Tera)를 Deep Learning으로 분석했을 때 얻게 되는 장점 및 실제 구현 사례를 살펴 봅니다. 기존의 Machine Learning 방법들보다 AI (Deep Learning) 방법의 장 단점을 살펴보고 어떻게 Deep learning을 적용할지 insight를 얻을 수 있을 것입니다.
최근 몇 년간 '딥 러닝'은 게임업계에서도 큰 이슈로 떠올랐다. 구글의 '알파고'의 사례 이후, 많은 게임사들이 딥 러닝에 대해서 연구하고 게임 서비스 등에 도입하려는 시도를 하고 있다. 게임을 서비스하면서 쌓이는 데이터의 양이 기존의 머신 러닝 기법으로 분석하기는 비효율적일 정도로 매우 거대해졌기 때문이기도 하다.
그렇다면 이런 딥 러닝을 통한 데이터 분석, 예측 기법으로 게임 데이터를 처리하는 게 어떤 도움이 될까? 크래프톤의 김승원 개발자는 이번 NDC 강연을 통해서 '테라'가 딥 러닝으로 데이터를 분석하고 학습하는 방법과, 이를 바탕으로 예측하는 모델을 직접 사례를 들어 설명했다.
■ 딥 러닝을 통한 데이터 분석, 테라의 사례
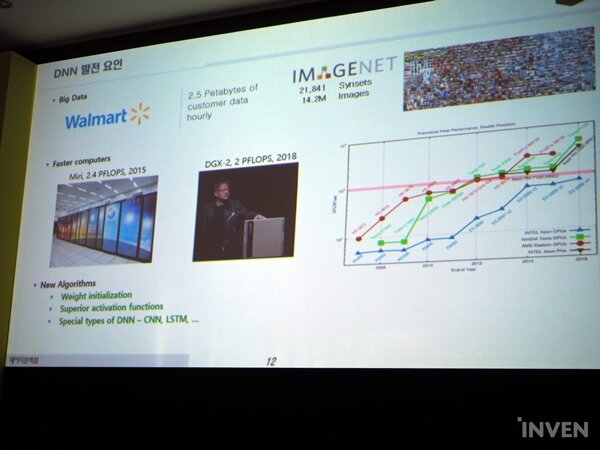
딥 러닝이라는 개념은 과거부터 있던 기법이다. 이미 딥 러닝의 기법과 백그라운드의 정의 자체는 1980년대에 정립이 되어있었다. 하지만 딥 러닝은 기본적으로 처리해야 하는 데이터의 양이 클 때 위력을 발휘한다. 데이터의 양이 많지 않을 경우, 머신 러닝 방법이 더욱 성능이 좋다. 보통 이미지에 대해서 데이터가 클래스당 1천 개 이상 되는 규모가 돼야 딥 러닝이 효과를 볼 수 있다.
하지만 최근에는 데이터가 폭발적으로 증가했다. 또한 신규 알고리즘이 정립되고, 컴퓨터의 성능이 과거보다 더욱 좋아지면서 머신 러닝 기법보다는 딥 러닝이 더욱 주목을 받게 됐다.
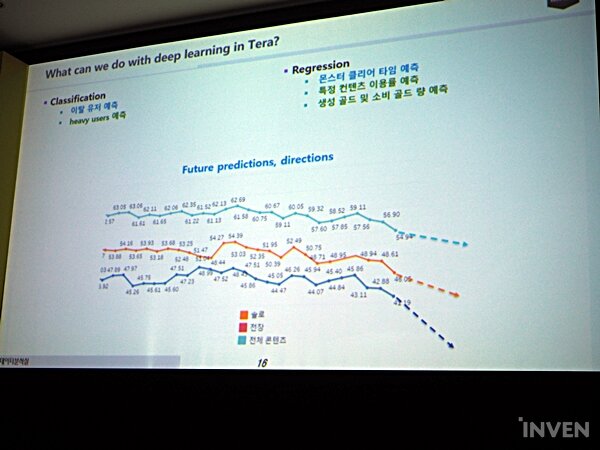
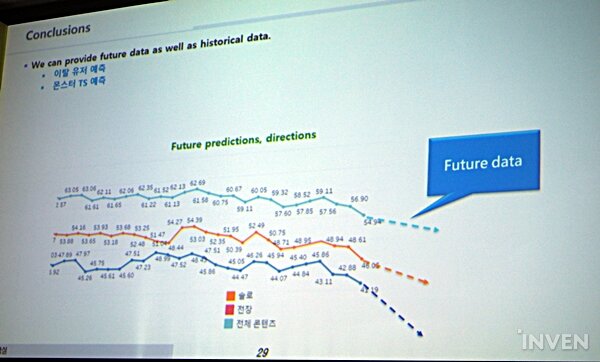
크래프톤은 현재 서비스 중인 '테라'에 딥 러닝을 통한 데이터 분석을 도입하여 운용하고 있다. 딥 러닝의 Classification(분류) 기법으로는 이탈 유저를 예측하고, Regression(회귀법) 기법으로는 몬스터 클리어 타임을 예측하는 방식이다.
(내용 수정 : 4/29 PM 12:29)이탈 유저를 예측하기 위해 현재 유저들의 데이터를 우선 분류하고, 이후 다음 달 유저들의 패턴 방식을 예측한다. 현재 크래프톤은 게임에 약 30일간 접속이 없는 유저들을 이탈 유저로 정의하고 있다. 이들을 예측하기 위해서 현재 활동 중인 유저들의 플레이 패턴을 만들어 정규화하고(Normalization), 표준화(Standardization) 한다. 그리고 이를 기반으로 다음 달 여전히 플레이 중인 액티브 유저(B)를 계산한다.
그리고 이번 달의 액티브 유저(A)와 다음 달의 액티브 유저의 교집합을 구하고, 이번 달 유저 중 차집합 군(A - B)에 속하는 유저들을 이탈 유저로 예측하는 형태다. 물론 현재 액티브 유저들도 매일매일 게임을 할 수 없으므로, 이런 유저들의 접속 빈도도 매우 중요하다. 이탈 유저는 보통 이 전달부터 접속률이 떨어지는 경향이 있기에, 이에 대한 예측과 학습도 만들어 최대한 모델의 정확도를 올리고 있다.

■ 딥 러닝을 통한 몬스터 클리어 타임 예측
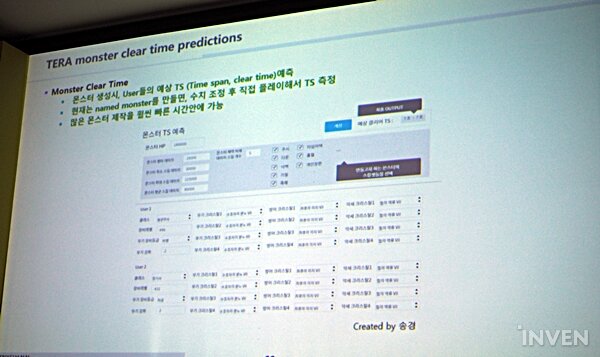
다음은 새롭게 제작한 몬스터의 클리어 타임을 예측하는 경우다. 새로 제작한 몬스터의 클리어 타임을 예측하기 위해서는 많은 데이터가 필요하다. 유저들의 레벨과 장비 구성, 아이템의 강화정도, 몬스터의 체력, 대미지, 스킬, 그리고 유저 파티 구성까지 다양한 데이터들을 도합하여 정규화하고 이를 기반으로 클리어 타임을 예측한다.
그러나 이 경우 한 가지 문제가 생긴다. 바로 '유저'들의 컨트롤 실력이다. 컨트롤 실력은 데이터화 하기가 난감하고, 예측을 해야 하는 모델 중 하나다. 크래프톤은 이를 예측하기 위해 두 가지 모델을 만들어서 실험을 진행했다. 첫 번째는 퍼시스턴스(Persistence) 모델로, 최근 데이터의 평균 값을 학습하여 미래의 몬스터의 클리어 타임을 예측하는 방법이고, 두 번째는 딥 러닝을 통해 과거와 현재 데이터를 학습해 예측하는 형태다.
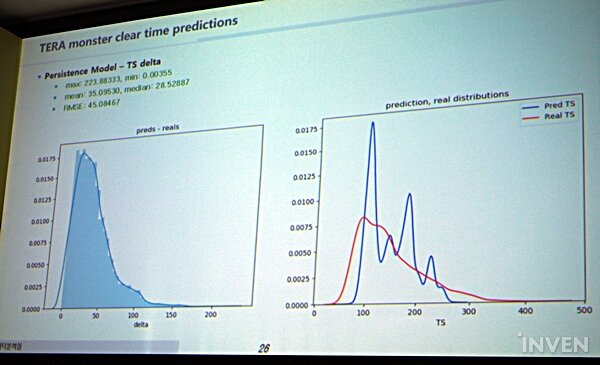
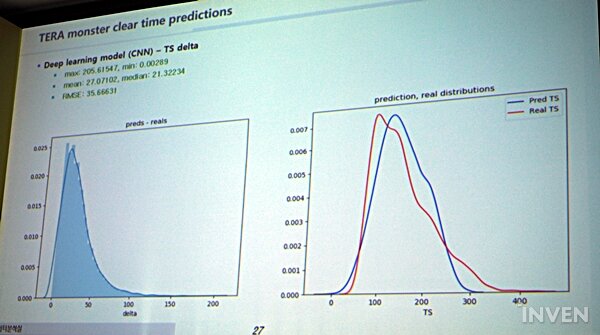
이 과정에서 퍼시스턴스 모델로 예측한 몬스터 클리어 타임 예측은 실제 클리어 타임과 '평균값' 자체는 비슷했지만 예측을 크게 벗어난 경우가 많았다. 반면에 딥 러닝 모델은 평균값뿐 아니라 실제 클리어 타임과 분포도 상당히 일치하는 결과를 얻었다. 실제로 딥 러닝 모델은 클리어 타임을 약 10초 정도 차이로 잘 예측을 하고 있었고, QA 팀에 문의해보니 40초 이내 차이면 충분히 의미 있고 괜찮은 수치라는 답변을 받았다고 한다.
김승원 개발자는 "게임 데이터를 가지고 지표를 생성하는 작업에서, 딥러닝은 QA에 도움을 주는 몬스터 클리어 타임의 예측이라던가, 서비스 이탈을 예측하여 서비스를 이용하게 만드는 기획에도 도움이 될 수 있다"라고 평가하면서 강연을 마쳤다.