










주제: 하스스톤 강화학습 환경 개발기 - 0티어 덱을 만들기 위해 떠나는 모험
강연자 : 옥찬호 - 넥슨코리아 / NEXON KOREA
발표분야 : 프로그래밍
권장 대상 : 게임 프로그래머, 카드 게임 개발이나 강화학습 환경 구축에 관심이 많은 프로그래머
난이도 : 사전지식 불필요 : 튜토리얼이나 개요 수준에서의 설명
[강연 주제] 이 세션에서는 하스스톤이라는 게임을 간단하게 설명하고 기존 게임과 어떤 부분이 다른지 살펴봅니다. 그리고 현재까지 하스스톤 강화학습과 관련해 진행되었던 연구들을 살펴보고 어떤 한계점을 갖고 있는지 설명합니다. 다음으로 약 1년 반 동안 하스스톤을 만들면서 어떤 기술들을 적용했는지, 그리고 개발하는 과정에서 어떤 어려움을 겪었고 해결했는지 이야기합니다. 마지막으로 강화학습을 위한 환경을 구축하기 위해 작업했던 내용들을 설명하고 완성된 학습 환경을 통해 AI를 어떻게 학습할 수 있는지 살펴봅니다. 이 발표를 통해 평소 하스스톤과 같은 카드 게임 개발이나 게임에 강화학습을 적용하기 위한 환경을 구축하는데 관심을 갖고 있던 프로그래머들에게 조금이나마 도움이 되었으면 합니다.
금일(26일), 경기도 성남시 판교에서는 NDC(Nexon Developers Conference)의 3일 차 행사가 진행됐다. 3일 차에는 총 29개의 강연이 준비되었으며, 넥슨코리아의 옥찬호 프로그래머는 금일 오후 연단에 올라 ‘하스스톤 강화학습 환경 개발기 - 0티어 덱을 만들기 위해 떠나는 모험'이라는 주제로 강연을 진행했다.
해당 강연에서 옥찬호 프로그래머는 하스스톤 AI 제작을 위한 강화학습 모델 구축 방법과 그동안 겪은 시행착오에 대해 논했다.
* 본 강연은 독자의 이해를 돕기 위해 강연자의 시점으로 서술되었습니다.
■ Step 1 - '하파고'를 만들자! 맨 땅에 헤딩으로...

컴퓨터(인공지능)와 하스스톤을 플레이하다 보면, 대체로 괜찮은 모습을 보여준다. 그런데 아주 가끔 이상한 일이 발생한다. 사람같지 않은 행동을 하는 것이다. 예를 들어, 종말의 예언자를 꺼내놓고 적 필드를 얼려놨다고 치자. 보통 이런 상황에서 상대방이 사람이라면, 아무런 행동도 취하지 않는다. 다음턴에 필드가 전멸할 게 뻔하기 때문이다.
그런데, AI는 돌연 얼려진 자신의 하수인에 버프를 준다. 그리고 다음 턴에 죽는다. 이런 상황이 종종 일어난다. 정말 ‘말도 안 되는 플레이’를 하는 것이다.
어느날 알파고와 알파스타를 보고, 하스스톤도 저렇게 변할 수 있지 않을까? 하는 생각이 들었다. 강화학습을 통해 프로게이머와 대적할만한 수준으로 AI를 만드는 것이 목표였다. 그리고 최대한 승률이 높은 덱을 만들고, 플레이어가 덱을 만들 때 필요한 대체 카드 추천 기능 역시 구현하고자 했다.
강화학습은 아이가 첫 걸음을 떼는 과정과 비슷하다. 아이는 걷는 것을 배운적이 없다. 스스로 이것저것 시도해보다가 우연히 걷게 된다. 에이전트 역시 사전 지식이 없는 상태에서 학습한다. 환경은 에이전트에게 보상을 주고, 다음 상태를 알려준다. 바로 이 행동과 보상이 이번 하스스톤의 강화학습의 핵심이다.

먼저, 알파고와 알파스타를 살펴보자. 알파고는 바둑판 위에서 필요한 모든 상황에 대한 정보를 얻을 수 있다. 바둑은 두 선수가 돌을 하나씩 번갈아 놓으며 진행한다. 즉, 제한 시간 내에 모든 상황에 대한 정보를 판단해가며 대국을 유리한 상황으로 이끌어가면 된다. 비교적 직관적이다.
반면, 스타크래프트는 실시간 전략 게임이며 알파스타는 알파고에 비해 불완전한 정보만을 제공받는다. 유닛의 시야에 의존해야하고, 실시간으로 넓은 전장에서 수백개의 유닛과 건물을 제어하며 전략을 짜야한다.
하스스톤은 더욱 더 불완전하다. 당장 본인의 덱에서 무슨 카드가 나올지 모른다. 상대가 무슨 카드를 들고 있을지 모르며, 역시나 무슨 카드를 뽑을지 예측할 수 없다. 정보가 완전하면 예측이 가능하지만, 모르는 정보 투성이라 불가능하다.

더군다나 ‘무작위’ 효과가 상당히 많아 결과를 추론하기가 힘들다. 카드를 냈을 때 어떤 효과가 어떻게 발생할지 모른다. 이런 무작위성 탓에 프로게이머 대결에서도 운에 기대는 모습이 종종 나온다. 어떻게 보자면, 연구하기 참 흥미로운 주제다.
게임을 활용해 강화학습을 하려면, 게임사에서 제공하는 API를 사용하는 방법이 있다. 하지만, 하스스톤은 아쉽게도 관련 API가 없다. 두번째는 게임을 후킹해서 정보를 얻는 것인데, 이는 위법이다. 결국 하스스톤을 직접 만들어 사용하는 수 밖에 없다. 모든 걸 직접 만들어야 했다.
■ Step 2 - '정보'는 얻었다. 하지만 '효과'는?

하스스톤은 전장, 영웅, 손, 영웅 능력, 덱, 묘지 총 6가지로 이루어져있다. 이걸 모두 개발해야 한다. 카드와 별개로 Entity를 별도로 설정했다. 카드는 순수히 카드 정보만을 가진 개체고, Entity는 게임에서 사용하기 위해 카드를 기반으로 새롭게 만든 개체다.
좀 더 자세히 설명하자면, 카드는 필드에 투입되면 버프를 받기도 하고, 침묵을 받기도 한다. 카드 정보에 직접 이런 효과를 적용하면 다음 게임에서 정상적으로 사용할 수 없기에 새로이 만들어 활용하는 것을 Entity라는 개체로 정의했다.
그렇다면, 카드 데이터를 어떻게 구해야할까? 카드 데이터는 어떻게 가져올 것이며, 카드 효과는 어떻게 인식할 것인가?

하스스톤에는 다양한 카드가 존재하며 갖고있는 데이터가 각각 다르다. 대표적으로 모든 카드는 마나 코스트를 지닌다. 하수인 카드는 공격력과 체력을 갖는다. 무기 카드는 공격력과 내구도를 갖고, 어떤 카드는 어빌리티와 비밀 같은 특수 능력을 지니고 있기도 하다. 이렇듯 갖고있는 데이터가 다 상이하다.
이러한 데이터 정보를 취득하기 위해 JSON 형태로 하스스톤 데이터를 제공하는 사이트를 이용했다. 해당 사이트에는 카드 동작을 구현하는데 필요한 ‘거의’ 모든 데이터가 존재했다.
해당 데이터를 바로 받아서 활용했는데, 한 가지 문제가 있었다. 카드 타입에 따라 종류의 데이터가 문자열 형태로 저장되어있다. 하지만, 키워드들을 열거체로 관리할 수 있으면 좋겠다 생각했고, 문자열을 열거체로 변환할 수 있는 방법을 찾았다.

Python-HearthStone라는 사이트에서 카드 데이터에 사용되는 다양한 열거체 타입을 정리해놨다. 여기에 등장하는 열거체를 Better-enums라는 라이브러리를 통해 문자열로 변환했다.
이제 남은 문제는 카드 효과를 처리하는 것이다. 하스스톤은 앞서 말했듯 고유한 효과를 지닌 카드가 많다. 예를 들어 단검 곡예사는 하수인을 필드에 내면 임의의 적 대상에게 피해를 1 주는 효과를 가지고 있다. 두억시니는 전투 중 발동한 전투의 함성을 반복하는 효과를 가지고 있다. 비밀은 특정 조건에 부합하는 상황이 나오면 효과가 자동으로 발동한다.
아직 문제가 남았다. 이렇게 다양한 효과를, 어떻게 처리해야할까?
■ Step 3- 구현해야할 카드가 6,086장?

현재 하스스톤 내에는 총 1,926장의 생성 가능한 카드가 존재한다. 하지만 이게 끝이 아니다. 예를 들어, 팔도레이 순찰자는 ‘잠복’ 카드와 4/4 스텟을 지닌 하수인 카드를 추가로 생성한다. 즉, 생성 가능한 카드에서 파생되는 생성 불가능한 카드가 별도로 존재한다. 여기에 모험 모드용 카드, 디버깅용 카드 등을 전부 합하면 무려 6,086장이다.
가장 이상적인 방법은 카드를 이미지로서 읽어 효과를 자동으로 생성하는 방법이다. 실제로 딥마인드에서 관련 연구를 진행해 어느정도 성과를 거둔 바 있지만, 몇몇 카드의 효과가 잘못 출력되는 등 불완전한 모습을 보였다.
결국 카드마다 효과를 직접 구현하는 방법이 남았다. 정말 힘들지만, 가장 확실하다. 다행히 효과가 없는 카드도 일부 존재하기 때문에 모든 카드를 구현할 필요는 없었다.
대표적인 카드 효과를 보자면, 플레이어가 카드를 손에서 낼 때 효과가 발동하는 ‘전투의 함성’, 하수인이나 무기가 파괴될 때 효과가 발동하는 ‘죽음의 메아리’, 지정된 대상에게 효과를 부여하는 ‘인챈트’, 하수인이 필드에 있는 동안 지정된 대상에게 지정된 효과를 유지하는 ‘오라’, 마지막으로 정해진 조건을 충족할 때 특정 효과가 발동하는 ‘트리거’가 있다.
만드는 방법을 살펴보자면, 전투의 함성과 죽음의 메아리는 태스크(Task)를 만들어 처리한다. 먼저 부모 클래스 ITask를 상속 받아야 한다. 그리고 순수 가상 함수 GetTaskID()와 Impl()을 구현해야 한다. 구현한 태스크는 Run() 또는 RunMulti() 함수를 호출해 실행할 수 있다.


예시로 방패 올리기를 구현해보자. 이 카드의 효과를 구현하기 위해선 어떤 태스크를 만들어야할까? 우선 ‘방어도 5’를 얻는 태스크와 ‘카드를 1개 드로우’하는 태스크가 필요하다. m_amount로 방어도를 얼마나 올릴지 구현할 수 있으며, 현재 방어도를 불러와 더해질 방어도의 값을 추가하는 방식으로 구현한다.
드로우 태스크 역시 똑같이 m_amount로 수치를 조정한다. 생성자 함수에서 몇 장이나 드로우할지 받아서 얼마나 드로우할지 결정할 함수를 호출한다. 탈진 데미지 관련 로직 역시 위에 위치해있고, 해당 로직을 통과, 즉 탈진이 아니라면 핸드에 추가하는 로직을 거친다. 카드가 꽉 찼으면 바로 묘지로 보내는 함수 역시 마련했다.
이러한 태스크를 통해 카드 효과를 등록하면 된다.
■ Step 4- 공격 한번 하는 것도 참 쉽지 않다

영웅과 하수인의 공격은 어떻게 구현할까? 우선 공격하기 전과 공격하는 순간을 나눠서 파악해야 한다. 영웅이나 하수인이 공격할 수 있는 상황인지, 공격할 대상이 유효한지, 공격할 대상이 빙결, 독성 등 특수 능력을 갖추고 있는지, 피해를 주고난 뒤 파괴할 수 있는지 등을 고려해야 한다.
제일 먼저 적용되는 로직은 ‘공격 가능 여부’다. 우선 공격자가 유효한지를 봐야 한다. 일단 공격력이 0이면 공격이 불가능하다. 빙결 상태 역시 안 된다. 이미 공격을 마쳤는지도 확인해야 하며, 이외 기타 불가능한 조건이 있는지 확인이 끝난 뒤에야 공격할 수 있다고 반환해주는 코드가 적용된다.
상대 카드의 유효성 확인은 그 대상을 유효대상 목록과 대조하는 형식으로 이루어진다. 우선 필드의 모든 하수인을 가져온다. 이후 타겟팅 불가능한 ‘은신’을 제외한다. 도발 하수인이 있으면 타겟을 이쪽으로 바꿔준다. 마지막에 영웅을 직접 공격할 수 있는지도 확인한다. 이 과정을 거쳐서 다시금 반환 코드를 적용한다.
이를 모두 확인하면 이제 로직을 거치면 된다. 빙결 효과, 독성, 대상의 공격력이 주는 반격 데미지, 공격자의 은신 해제, 무기 내구도 하락, 카드 파괴 등의 로직을 거쳐야 한다. 마지막으로 ‘질풍’ 효과 로직을 처리한다. 질풍 여부를 따져서 카드가 완전히 탈진 상태인지 아닌지를 지정해주고, 관련 오라나 하수인 죽음 여부를 적용해준다. 물론 이 외에도 수많은 로직이 존재한다.
■ Step 5- 15분 남짓한 시간, 게임 속에서는 16단계가 돌아간다.
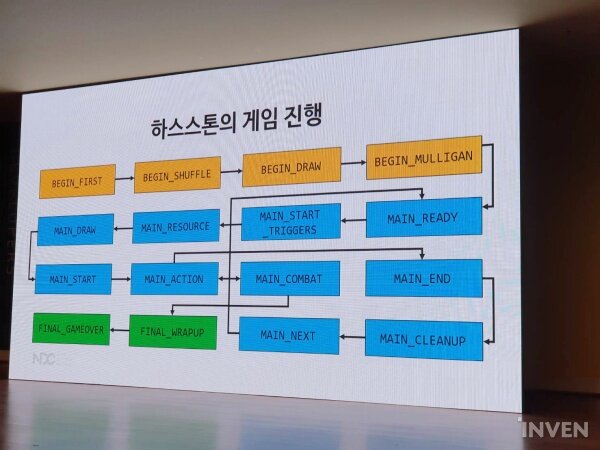
하스스톤은 16단계의 진행을 거친다. 우선 게임의 시작 관련 로직을 수행하는 ‘비긴 퍼스트’ 단계, 덱에 있는 카드를 무작위로 섞는 ‘비긴 셔플’ 단계, 카드를 뽑는 ‘비긴 드로우’ 단계, 그리고 마음에 들지 않는 카드를 다시 뽑는 ‘비긴 멀리건’ 단계가 초반을 담당한다.
이후 메인 단계로 넘어간다. 영웅, 무기, 하수인의 공격 가능 횟수를 초기화하는 ‘메인 레디’ 단계, 턴을 시작할 때 동작하는 트리거를 호출하는 ‘메인 스타트 트리거’ 단계, 마나 수정을 1개 추가하고 모두 채우는 ‘메인 리소스’ 단계, 그리고 덱에서 카드 1장을 뽑는 ‘메인 드로우’ 단계가 있다.
이후 본격적인 전투에 들어간다. 플레이어의 턴을 시작할 때 처리해야 할 로직을 수행하는 ‘메인 스타트’ 단계, 플레이어의 행동을 처리하는 ‘메인 액션’ 단계, 하수인이 상대편의 하수인이나 영웅을 공격하는 ‘메인 컴뱃’ 단계, 그리고 플레이어의 턴이 끝날 때 처리해야 할 로직을 수행하는 ‘메인 엔드’ 단계로 전투가 이루어진다.
이 외에도 한 턴만 지속되는 효과를 제거하는 로직을 수행하는 ‘메인 클린업’ 단계, 상대 플레이어에게 턴을 넘기는 ‘메인 넥스트’ 단계가 있다.
전투가 마무리되고 게임의 승패를 처리하는 ‘파이널 랩업’ 단계와 게임 관련 데이터를 정리하고 종료하는 ‘파이널 게임 오버’ 단계를 거치게 된다.
■ Step 6- 한국의 '하파고'를 위해, Rosetta Torch 프로젝트

AI가 하스스톤 게임을 하도록 만드려면 행동을 하기 위한 통로를 만들어줘야 한다. AI가 결정한 값을 게임에 전달할 수 있어야하기 때문이다. 이를 위해선, 정책 클래스를 구현해야 하는데 ‘넥스트(Next) 함수’, ‘리콰이어(Require) 함수’, ‘노티파이(Notify) 함수’가 필요하다.
넥스트 함수는 게임에서 다음에 수행할 행동을 반환하는 작용을 한다. 리콰이어 함수는 현재 하려는 행동에 대한 필요한 정보를 받는 역할을 하며, 노티파이 함수는 게임에서 발생한 부가 정보를 직렬화해서 보낸다.
하스스톤의 강화학습 환경을 구성하기 위해 PyTorch C++ API(LibTorch)를 사용했다. Pytorch는 Python 기반의 오픈 소스 머신 러닝 라이브러리로 C++ 기반의 머신러닝 모델 설계에 용이하다.
현재 옥찬호 개발자를 필두로 PyTorch C++ API 기반 정책을 위한 Rosetta Torch 프로젝트가 시작됐다. 프로젝트는 PyTorch 기반의 정책 클래스를 담당하는 TorchPolicy, 현재 게임 상태에서 취할 수 있는 행동 벡터를 알아내는 AvailableActions, PyTorch 기반의 딥러닝 모듈 ModuleBase, 게임 상태를 벡터로 취합하는 인터페이스인 GameToVec을 포함한다.

이중 GameToVec 클래스는 특히나 중요하다. 상대방의 필드, 나의 손, 덱에 있는 카드의 정보를 벡터로 표현하는 역할을 맡는다. 마나 비용, 공격력, 체력 값은 0~1 사이의 값을 갖도록 정규화하고, 이때 공격력과 체력의 타입은 int32인데 일정 값보다 크다면 비슷한 상황이라 판단해 CLIP_NORM(64) 이상은 1, 이하는 64로 나눈 값을 채택한다.
각 효과 정보를 인덱싱한 뒤 임베딩 룩업 테이블에서 벡터를 검색할 수도 있다. 예를 들어, GameTag::ATK이 1이고, EffectOperator::SET이 3이라면, 1*3=3, 즉 3번 인덱스를 통해 3번 벡터를 찾을 수 있다.
현재 이 클래스는 총 675 차원의 벡터로 게임을 표현하고 있다.
현재까지 구현된 카드는 대부분 오리지널에 머물러있다. 모든 카드를 구현할 예정이나, 오리지널을 먼저 완성한 뒤 확장팩 카드로 넘어갈 계획이다. 콘솔 및 GUI 프로그램을 개선해 AI와 대전할 수 있게 만들 예정이며, 다른 언어에서 사용할 수 있도록 API 역시 제공할 계획이다.

