['유나이트 서울 2018' 발표자 소개] 김인성 개발자는 현재 유니티 코리아에서 필드 엔지니어로 활동하고 있다. 필드 엔지니어는 유니티 엔진을 사용할 때 개발사가 겪는 여러 가지 기술적 어려움에 대한 해결을 도와주는 일을 한다.
유니티 엔진은 편한 게임 개발을 위해 생겨났다. 그리고 에셋은 게임 개발을 더욱 수월하게 도와주는 도구다. 에셋을 영리하게 사용한다면 게임 개발 시간 단축은 물론 퀄리티 향상까지 기대할 수 있다. 유니티 코리아의 김인성 필드 엔지니어는 서울 코엑스에서 개최된 '유나이트 서울 2018'에서 개발자를 대상으로 에셋번들 사용에 대한 실전 가이드를 제시했다. 이 강연에서 에셋번들 시스템에 대한 기본 소개와 구조, 빌드 과정에 대한 기술적 설명이 이루어졌다. 그리고 실제 개발 과정에서 발생한 좋은 사례와 나쁜 사례를 해설하고 해결 방안을 소개했다.
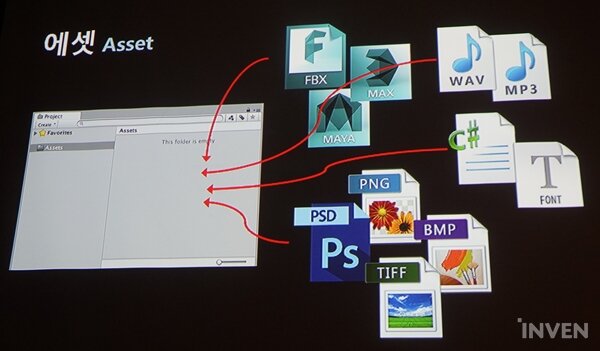
에셋은 유니티로 게임을 만들 때 쓰이는 이미지, 텍스트, 오디오, 애니메이션 데이터 등을 의미한다. 각 파일을 특정한 에셋 폴더에 모아 사용하게 된다. 에셋을 가져와 사용하는 걸 흔히 '임포트 한다'고 말하는데, 이때 각 에셋별로 고유의 메타 타입이 생겨난다. 에셋 메타 정보에는 파일 GUID 및 로컬ID, 생성 시간, 타입 등 각종 정보가 표시되어 있다.
만약 에셋을 외부에서 다른 폴더로 이동 후 다시 임포트할 경우 GUID 값이 변한다. 내용은 같더라도 GUID가 달라질 경우 유니티 에디터는 새로 임포트 된 에셋을 '다른' 에셋으로 인식하게 된다. 김인성 엔지니어는 "이 경우 이전 에셋에 연결한 링크가 끊어지기 때문에 주의해야 한다"고 강조했다.
'에셋번들'은 여러 에셋들을 하나로 묶어주는 파일 포맷이다. 이런 에셋번들은 다양한 파일과 '매니페스트 파일'로 구성된다. 에셋번들은 사용될 때 직렬화(serialization), 역직렬화(deserialization) 과정을 거치게 된다. 직렬화 과정은 오브젝트의 데이터를 순서대로 나열하는 과정이다. 순서대로 나열된 데이터는 다른 파일, 데이터 베이스, 메모리를 거쳐 다시 데이터 조립 가정을 거쳐 오브젝트가 된다. 뒤의 과정이 역직렬화 과정이다.
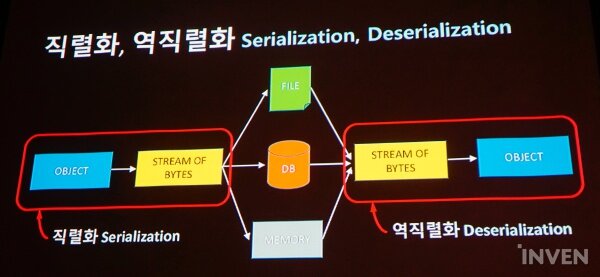
유니티에서 직렬화(Built in serialization)은 다양하게 쓰인다. 기본적인 파일의 읽기와 쓰기 과정도 직렬화이다. 에디터로 쓰이는 '인스펙터 창(inspector window)'과 스크립트 리로딩(reloading scripts), 프리팹(prefabs), 인스턴싱(instantition), '리소스 폴더'도 직렬화 작업을 거친다.
여기서 김인성 엔지니어는 '리소스 폴더'는 되도록 사용하지 않기를 권했다. '리소스 폴더' 자체는 여러 에셋번들을 넣고 사용할 수 있지만, 앱에 같이 묶여 들어가기 때문에 사용 유무에 상관없이 패키징되기 때문이다. 즉, 리소스 폴더가 많이 들어가게 된다면 앱 크기가 커진다. 앱이 커지면 시작할 때 리소스 파일 읽는 작업도 커져서 실행이 느려진다. 그렇지만, "앱에서 처음부터 끝까지 반드시 사용될 경우 리소스 폴더에 넣어도 무관하다"고 그는 덧붙였다.
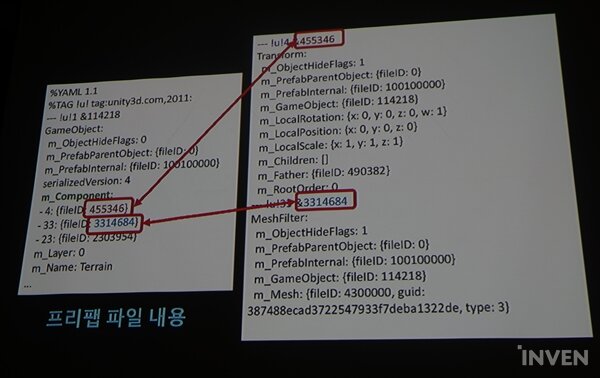
프리팹이 텍스트로 안 보이는 경우가 있다. 이때는 Asset Serialization 모드에서 forct text를 'force Text'로 설정하면 된다. 김인성 엔지니어는 'Force Binary'로 저장하면 빠를 수는 있지만, 유지 보수가 힘들다고 설명했다. 위 예시 이미지에서는 Transform 정보와 MeshFilter의 정보를 볼 수 있으며 둘 다 직렬화된 것을 확인할 수 있다.
■ 에셋번들 빌드 파이프라인
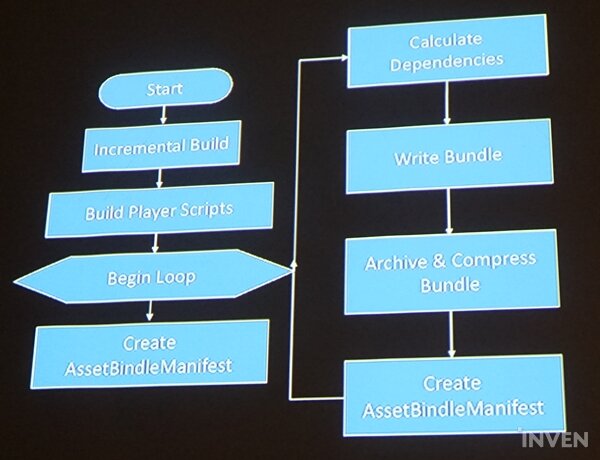
에셋번들이 실행되면 incremantal build에서 '수정이 안 된 것'을 빼고 빌드를 시작한다. 다음으로 build script를 확인해 루프를 시작하는데, 여러 에셋번들을 모으고 압축하는 manifest를 만든다. 더이상 작업할 게 없다면 위 시퀀스는 종료된다. 김인성 엔지니어는 "보통의 개발자는 굳이 알 필요 없고 참고용 이미지다"라고 소개했다.
그는 구성된 에셋번들의 분석 방법으로 두 단계를 소개했다. 먼저 WebExtract는 개발자가 분석하길 원하는 파일을 적어둔 뒤 각 OS의 커맨드 창에서 파일 위치를 확인한 뒤 추출한다. 그리고 binary to text로 에셋번들 파일을 텍스트 파일로 변환시킨다.


■ 에셋번들 구성 가이드
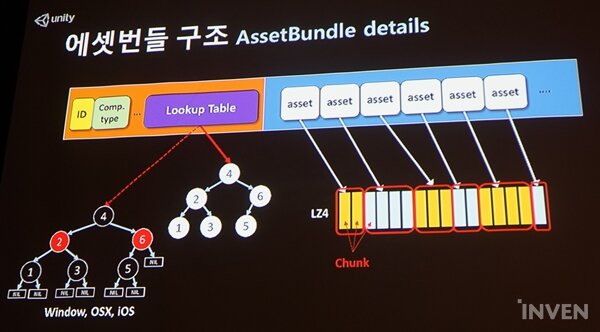
에셋번들의 구조는 header와 data segment로 나뉜다. 헤드는 에셋번들의 식별 정보인 id와 컴퍼넌트 파일이 있으며, 인덱스에 해당하는 lookup table로 구성된다. 데이터 세그먼트는 여러 에셋 정보가 담겨있다. 그리고 김인성 엔지니어는 "중요한 것은 압축 방식"이라고 소개했다.
압축 방식은 LZMA와 LZ4로 나뉜다. 그는 "LZMA은 압축은 잘 될 거 같은데, 비효율적일 거 같다"라면서 LZ4 방식을 권했다. LZMA가 에셋을 통으로 압축하는 방식이라면, LZ4는 에셋을 chunk로 나누어 효율적으로 압축하는 방식이다. 만약 에셋이 chunk보다 크면, 여러 chunk로 저장해 효율적이다.
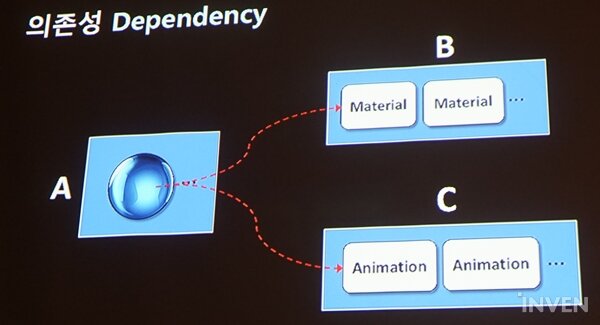
더불어 김인성 엔지니어는 에셋번들의 의존성(dependency)를 간략하게 설명했다. 금속 재질의 움직이는 구가 있을 경우, 재질과 애니메이션 에셋을 따로 만들어 구에 연결할 수 있다. 이때, 구는 재질 에셋과 애니메이션 에셋에 의존적이다. 만약 에셋 링크가 끊길 경우 개발자는 기본 형태인 안 움직이는 보라색 구만 보게 된다.
개발하다 보면 프로그래머는 최적의 에셋번들 개수를 고민하게 된다. 이에 김인성 엔지니어는 "정해진 답이 없다"고 전한다. 만약 너무 적은 에셋번들을 가지고 있을 경우 실행할 때 메모리 사용량이 증가한다, 따라서 로딩 타임이 길어지고, 다운로드양이 증가하게 된다. 다운로드양이 증가하면 업데이트에 불리하다.
너무 많은 에셋번들을 가진 경우에도 문제가 있다. 프로그래머의 빌드 시간이 증가하고, 개발을 복잡하게 만들 수 있다. 개발이 복잡해지면 추후 유지 보수 작업이 어려워진다. 그리고 전체 다운로드 시간이 늘어난다. 정해진 적절한 에셋번들 개수가 없기에 작업자가 스스로 판단해야 한다.
고민하는 개발자들을 위해 김인성 엔지니어는 '그룹화 방식' 가이드를 제시했다. 먼저 종류별 그룹화는 오디오 트랙 또는 국가별 언어 파일 등 같은 타입 별로 그룹화를 맺는 방법이다.
논리적 그룹화 방식은 UI, 캐릭터, 환경 등 논리적으로 묶을 수 있는 요소를 그룹화하는 것이다. 이 방식은 DLC에 적합하다. 그리고 각 에셋번들이 언제, 어디서, 어떻게 사용될지 프로그래머가 정확히 알고 있을 때 논리적 그룹화 방식이 유용하다.
동시에 사용하는 콘텐츠별로 그룹화를 할 수도 있다. 각 레벨별 사용하는 모든 캐릭터, 텍스처, 음원을 하나로 그룹화하는 방법이다. 레벨1과 레벨2를 동시에 로드하는 경우가 없을 때 콘텐츠별 그룹화가 유용하다. 김인성 엔지니어는 "세 방법에 정답은 없으며 적절히 번갈아 사용해야 한다"고 조언했다.
그리고 자주 변경되는 것과 그렇지 않을 것을 분리하고, SD/HD(저화질/고화질) 에셋처럼 절대 동시에 로드하지 않는 에셋들을 그룹화하는 것이 좋다고 덧붙였다. 번들 내 50% 이하의 사용률을 보이는 에셋도 분리를 고려하는 것이 좋다. 반대로 적은 수의 에셋을 가지며 자주 로드하는 에셋번들은 통합하는 것이 유용하다. 만약, 같은 오브젝트의 그룹이고 버전만 다를 경우 Variants를 고려해보라고 그는 권했다.
에셋번들 버라이언트(variants)는 지정한 플랫폼에 알맞은 에셋번들을 쉽게 로딩하게끔 한다. 안드로이드도 기기마다 화면 크기 차이와 성능 차이를 보인다. 이때도 각각 버라이언트로 다른 에셋번들을 로드할 수 있다. 버라이언트의 제한 사항으로 김인성 엔지니어는 "버라이언트마다 각각의 에셋이 파일로 존재해야 한다"고 전했다.
또한 다섯 개의 베리언트 중에서 하나를 수정하면, 다른 4개를 수정하지 않을 경우 최종 결과가 달라질 수 있다. 아직 이 문제의 해결책은 없으며 추후 업데이트를 통해 해결되길 기대한다고 그는 덧붙였다.

■ 에셋번들 다운로드
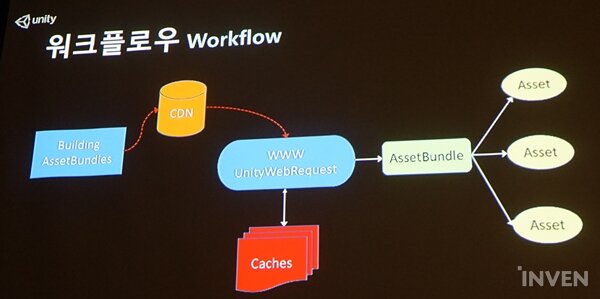
에셋번들을 구성하면 CDN에 파일을 올리고, 웹에서 많이 쓰던 WWWUnityWebRequest로 보낸다. 이때 유니티가 제공한 API를 사용하면 자동으로 캐싱 된다. 확인 후 에셋번들이 캐싱 되어 있으면 다음 함수를 호출해 캐쉬를 가져온다. 그리고 파일이 완성될 때까지 작업이 반복된다.
문제는 5.6버전 이하에서는 오래된 캐쉬 파일이 삭제되지 않고 누적되며 업데이트된다는 점이다. 만약 500메가의 업데이트를 배포했을 시, 기존 자료에 누적되어 업데이트된다. 즉, 500메가 파일만 필요한데 1기가의 파일이 될 수도 있다. 누적된 자료는 기기의 제한 용량까지 차오르고, 제한을 넘어설 경우야에 캐쉬 파일이 삭제된다. 이 문제는 2017.1 버전에서 해결됐다.
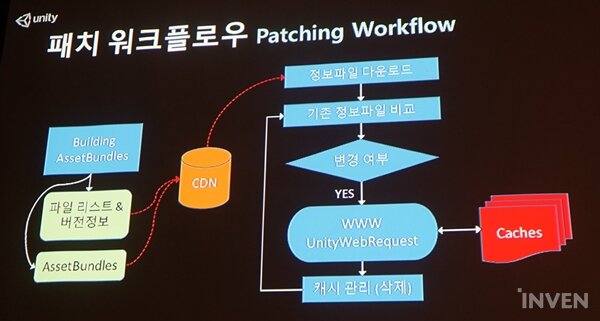
패치 워크플로우는 기존 정보와 비교하는 과정이 추가된다. 에셋번들이 수정됐을 경우 다운로드 된다.
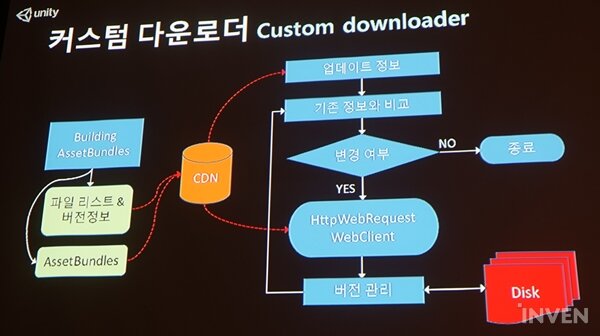
직접 커스텀할 경우 HttpWebRequest 및 WebClient를 사용하게 된다. 김인성 엔지니어는 "굉장히 하드코어한 프로그래머가 아니라면 말리고 싶다"고 전했다. 사용할 경우 압축 방식은 LZ4를 사용하고, 앱은 지워지지 않고 수정할 수 있는 곳에 저장하라고 전했다.
이어서 김인성 엔지니어는 에셋번들 로딩에서 많이 쓰는 다섯 가지를 소개했다.

FromMemory는 C#의 메모리를 네이티브 메모리로 복사한다. LZMA는 메모리에 압축을 해제하고, LZ4 및 압축되지 않은 에셋번들은 복사본을 생성한다. 이 과정에서 최소 2배의 메모리가 사용된다. 원본 메모리와 복사본 메모리가 쓰이며, 경우에 따라 3배까지로 늘어난다. 그는 이 방식을 추천하지 않았다.
FromFile은 LZ4 또는 무압축용 고효율 API다. 에셋번들의 헤드만 로드하고 데이터 부분은 로드하지 않는다. 파일에서 직접 가져오니 효율적이며, 에디터는 에셋번들을 메모리에 로드한다. 그래서 에디터에서 프로파일링할 때 메모리 사용량이 많이 표시될 수는 있다. 그러나 이 방식은 5.3 버전 이하에서는 안드로이드 기기의 StreamingAssets 폴더를 읽지 못하는 버그가 있다. 5.4 이상에서는 해결됐지만, 5.3 이하에서는 사용하기 곤란하다.
FromStream 방식은 성능 최적화를 위한 제약 사항이 많다. 먼저 에셋번들 데이터는 반드시 스티림의 제로 위치에서 시작해야 한다. 그리고 데이터를 읽기 전에 seek 포지션을 0으로 설정해야 하고, 스트림의 읽기 위치가 다른 프로세스에 의해 변경되지 않을 거라고 가정해야 한다. 또한, stream.CanRead와 CanSeek은 반드시 true 값을 리턴해야 한다.
FromCacheOrDownload는 2017.1 버전 이상에서 사용할 수 있다. 내부에서 UnityWebRequest API를 사용한다. 그런데 이 API는 추후 없어질 예정이다. 5.6 버전 이하에서는 www를 사용할 때 메모리 오버헤드 현상이 발생한다. 호출할 때마다 worker thread가 생성되며, 되도록 한 번에 하나씩 다운로드하는 게 좋다. 동시에 5개 이상의 다운로드가 필요할 경우 별도의 다운로드 큐를 제작해 사용한다.
DownlloadHandlerAssetBundle은 WWW.LoadFromCacheOrDownload과 비슷한 작업을 수행한다. 워커 스레드를 사용해서 다운로드된 데이터를 고정 크기 버퍼에 스트리밍하고, 다운로드 핸들러의 구성에 따라 버퍼링 된 데이터를 임시 저장소나 애셋번들 캐시에 스풀링한다. LZMA 압축된 애셋번들은 다운로드 동안 압축 해제되고 압축되지 않은 캐시로 저장된다.
모든 연산은 네이티브 코드상에서 수행되며, 힙이 확장될 위험성을 제거한다. 또한, 다운로드 핸들러는 다운로드된 모드 바이트들에 대한 네이티브 코드 복사본을 유지하지 않는다. 그리고 애셋번들을 다운로드하는 데 필요한 메모리 오버헤드를 줄여줍니다.
다음으로 김인성 엔지니어는 에셋번들의 로드와 언로드에 대한 설명을 이어갔다. 에셋번들 로드에 사용되는 메모리는 내부 캐싱 되어 있거나 LoadFromFile로 로드한 경우 최소화된다. 다만, 드물게 에셋번들 1개당 수십kb의 메모리를 사용하는 경우가 더러 있다. 이때 아주 많은 에셋번들을 한 번에 로드할 경우 문제가 생길 수 있다.
부적절하게 언로드를 하면 에셋 중복 문제가 발생하거나 특정 에셋이 빠지는 경우가 발생한다.
■ 에셋번들 문제와 해결 방법
에셋번들에 명시적으로 할당되지 않은 에셋의 경우, 에셋이 참조하는 모든 에셋번들에 에셋의 복사본이 포함된다. 이때 각 복사본은 각기 다른 에셋으로 처리되어 별도의 메모리를 차지하게 된다. 오브젝트 요소 중 하나라도 할당되지 않은 에셋을 참조해도 같다.
김인성 엔지니어는 위 문제의 해결 방법으로 명시적 에셋번들 할당을 하라고 조언했다. 그리고 각 에셋번들 간 종속성을 없애고, 하나의 종속성을 공유하는 두 개의 에셋번들이 동시에 로드되지 않도록 분할하라고 권장했다. 연관성 있는 에셋들을 하나의 에셋번들로 빌드하는 것도 방법이다.
스프라이트 아틀라스의 중복 문제는 자동 생성된 스프라이트일 경우, 스프라이트가 포함된 에셋번들에 아틀라스도 할당되는 문제다. 스프라이트가 여러 개의 에셋번들에 할당된 경우 각각을 복제한다. 스프라이트를 에셋번들에 할당하지 않으면, 아틀라스도 할당되지 않는다. 이 때문에 2017.1 이상의 버전일 경우 SpriteAtlas 에셋을 사용한다.
5.2.2p3 이하의 버전일 경우 자동 생성된 아틀라스가 에셋번들에 할당되지 않는다. 이로 인해 스프라이트를 참조하는 모든 에셋번들에 복사본이 포함된다. 김인성 엔지니어는 5.2.2p4 또는 5.3 이상의 버전으로 업그레이드하길 권장했다.
안드로이드 텍스처 문제는 다양한 기기에 다른 텍스처가 지원된다는 문제다. OpenGL ES 2.0과 3.0 동시 지원을 위해 ETC1을 사용하게 되는데, ETC1은 알파 채널을 지원하지 않는다. OpenGL ES 2.0만 지원하는 경우 배리언트를 사용해 2와 3의 에셋번들을 별도로 준비하면 된다. 단, GL ES 2.0에는 디바이스 전용 포맷의 텍스처가 포함되야 한다.
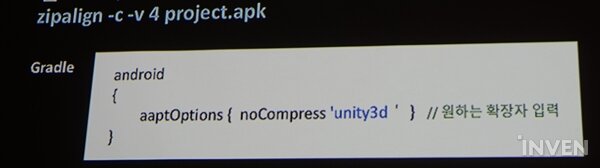
간혹 안드로이드에서 로딩 속도가 느린 문제가 발견된다. 유니티로 빌드하지 않고 안드로이드 스튜디오로 제작해, 빌드된 에셋번들을 APK에 포함시킬 경우 문제가 발생한다. 해결 방안은 먼저 APK에 포함되는 에셋번들이 압축되어있지 않는지 안드로이드 SDK에 포함된 zipalign으로 확인한다. 확인 코드 예제는 다음과 같다.