
[인벤게임컨퍼런스(IGC) 발표자 소개] LG전자 MC연구소를 거쳐 엔씨소프트의 AI LAB / Game AI 개발 팀장으로 재직 중이다. 블레이드앤소울 무한의 탑 AI 개발을 담당했다.
AI(Artificial Intelligence). 인공지능은 철학적인 관점에서 인간성이나 지성을 갖춘 존재, 혹은 시스템에 의해 만들어진 지능, 즉 인공적인 지능을 뜻한다.
게임에서 AI는 전통적인 의미의 단순한 NPC AI부터 자가 업데이트가 가능한 AI까지 다양하게 존재한다. 알파고 처럼 학습하는 AI가 있는가 하면 모바일 게임의 '자동전투'처럼 행동이 패턴화된 AI도 존재한다.
엔씨소프트의 이경종 AI LAB/Game AI 팀장은 IGC2016 강단에서 기계 학습을 이용한 NPC AI 제작 방법과 강화 학습 적용 사례를 소개했다. 아울러 이를 상용화하는 과정에서 발생하는 문제점과 해결 방법을 공유하고 R&D 과정에서 이용할 수 있는 실험 과정과 에피소드도 청중에게 전달했다.
■ 강연주제: 강화 학습을 이용한 NPC AI 구현
⊙ 게임 AI는 무엇인가
강화 학습(Reinforcement Learning)이란 AI를 만들고 만든 AI를 바탕으로 콘텐츠를 만드는 과정 중 하나다. 게임에 필요한 AI 기술은 다양하다. NPC AI를 비롯해여 Strategic, Tactical AI 등 다양한 기술이 있으며 게임에 필요한 기능을 AI를 활용해 개발하는 경우도 있다. Matching이나 Game interface가 대표적이다.
전통적인 게임 AI는 똑똑한 상대방을 만드는 것이었다. 체스나 바둑을 둘 때 상대방을 생각하면 이해가 빠르다. 과거에는 무브먼트(Movent)나 패스-파인딩(Path-finding)을 비롯한 의사 결정(Decision making), 보드 게임에서 사용하는 적대 탐색(Adversrial Search)가 관심 분야 였다.
하지만, 딥 러닝(deep learning, 심화학습)을 중심으로 많은 동향의 변화가 있다. 대표적으로 알파고 이벤트가 이러한 추세를 보여주는 좋은 예다. 최근에는 몬테카를로 트리 서치(Monte Carlo tree search, MCTS) 기반의 의사결정과 유전 알고리즘(Genetic Algorithm) 기반의 AI 그리고 일반적인 게임 플레이에 있어 강화 학습으로 추세가 변화했다.

이는 게임 AI를 바라보는 관점이 변화했기 때문에 나타난 현상이다. 게임은 하나의 거대한 가상 현실 세계이다. 가상 현실 세계에는 많은 것이 살아 숨 쉬고 있는데 이들은 AI로 만들어진다. AI가 중요할 수밖에 없다. 학술적인 측면에서도 게임은 AI 연구 개발에 있어 완벽한 플랫폼이다. 현실은 복잡하며 실제로 연구를 해볼 수 있는 상황이 제한적인 데 반해 거대한 가상 현실 세계인 게임은 시뮬레이션을 할 수 있게 좋은 무대를 제공한다. 실제로 알파고가 바둑 서비스를 하려고 만든 AI가 아님에도 바둑이라는 플랫폼을 통해 성능을 시뮬레이션하고 있다.
또한, 비주얼 둠 AI 대회(Visual Doom AI Competition)는 FPS 게임인 둠(Doom)을 플랫폼으로 삼아 기계 학습 한 AI만 플레이어로 참여할 수 있는 게임 대회도 존재한다. C++이나 파이썬, 자바로 프로그래밍한 AI를 기계 학습시켜 데스메치 형태로 대결을 펼치는 방식이다. 입력 데이터로 로 비주얼(Raw Visual)데이터만을 사용한다는 것이 특징이다.
엔씨소프트 Game AI팀은 기술을 바탕으로 어떻게 하면 새로운 콘텐츠를 만들 수 있을지, 어떻게 하면 AI를 활용하여 더 재미있는 콘텐츠를 만들 수 있을지를 연구하고 개발하는 역할을 하고 있다.
좀 더 자세히 이야기하자면 기계학습(Machine Learning)과 플래닝(Plannig) 등의 기술을 활용하여 알고리즘을 개발하여 프로토타입(Game AI Prototype) 및 라이브러리(Library)를 제작한다. 또한, 기계 학습 환경, 실험 게임 환경 등 AI R&D Framework을 개발하는 일을 하고 있다. 이들의 결과물 중 대표적인 것이 MMORPG인 '블레이드 & 소울'의 신규 콘텐츠 '무한의 탑'이다.
⊙ 무한의 탑
'무한의 탑'은 동양 세계관 무협 액션 MMORPG '블레이드 & 소울'에서 2016년 1월 오픈한 신규 콘텐츠로 AI와 1:1 비무를 하는 콘텐츠다.
'블레이드 & 소울'에는 본래 1:1 PvP 콘텐츠인 '비무'와 개인 PvE 콘텐츠인 '무신의 탑'이 존재했다. 그러나 비무는 진입 장벽이 높다는 점과 다른 사람과 대결에 대한 거부감이라는 한계점이 존재했고, 무신의 탑은 보스 몬스터의 고정된 패턴으로 정형화된 해법이 존재해 어느 정도 한계가 있는 콘텐츠였다.
무한의 탑은 이 두 콘텐츠를 AI를 활용하여 보완한 결과물이다. 난이도 별로 배치된 AI에게 승리하면 위층으로 진행하는 구조이며 무한의 탑 AI는 무신의 탑 AI와 다르게 패턴이 존재하지 않는다. AI가 상황에 맞게 판단하고 기술을 선택한다. AI들이 각각의 상황에 맞게끔 최적의 선택을 하며 다양한 상황을 연출해 낸다.
이러한 AI에게는 현재 상황을 판단해 스킬 셋을 선택하는 것이 필요하다. 현재 상황 즉, 자신의 체력, 상대의 체력, 상대의 상태, 스킬 쿨타임, 마나 등등을 통합적으로 판단하여 지금 사용해야할 최적이 스킬이 무엇인가를 고를 수 있어야 한다.
사실, 개념적으로는 매우 간단하다. 그러나 상용 게임에 적용하기는 쉽지 않았다. 왜냐하면, 게임 자체가 복잡한 규칙을 지니고 있기 때문이다. 게임 내 클래스별로 50여 개의 다양한 액션과 확률 요소를 지니고 있으며 이들은 실시간으로 전투를 치른다.
바둑이나 체스처럼 주고받는 형식이 아니라 실시간으로 일어나는 전투이기 때문에 1초에 몇 번씩 액션을 수행해야만 한다. 게다가 하나의 액션이 시작되고 온전히 종료되는 것이 아니라 액션 사이에 상대가 대응을 하므로 매우 복잡하고 다양한 상황에 대해 대응을 할 수 있는 AI가 필요하다.
그런데 이런 AI는 전통적으로 NPC를 제작할 때 사용하던 FSM(Finite-state machine)이나 행동 트리(Behavior Tree) 등 규칙 기반 기법으로는 구현할 수 없다. 그래서 엔씨 게임 AI팀은 강화 학습 기반의 NPC AI를 제작하기로 한다.
⊙ 강화 학습(Reinforcement Learning)
강화 학습을 한마디로 정의하자면 반복된 시도(Trial)와 오류(Error) 과정에서 피드백으로 학습하는 것을 뜻한다. 이를 '지도자 없는 가르침(Learning Without a Teacher)'라 부르는데 아기의 학습 과정과 본성을 모델링 한 학습 방법이다.
아기는 자라면서 부모의 정확한 지시 없이도 많은 시도를 하며 해도 괜찮은 것과 하지 말아야 할 것을 체득한다. 예를 들어 무언가를 먹었을 때 맛이 있었다면 맛있다는 긍정적인 피드백을 기억하며, 무언가를 먹었을 때 맛도 이상하고 엄마가 화를 내는 것 같다는 느낌이 들면 부정적인 피드백으로 기억하는 것이다. 이 과정을 반복하다 보면 아기들은 자연스럽게 어떤 것을 해야 하는지 알 게 된다. 강화 학습의 과정이 이렇게 이뤄진다.
로봇으로 강화학습 기반 AI를 시도한 사례도 있다. 팬케이크를 뒤집는 이 로봇에 AI를 탑재하여 로봇 팔의 움직임을 제어하게 했다. AI는 각 관절에 입력되는 힘을 조절할 수 있다. 팬케이크를 뒤집기 위한 시도를 하고 실패하면 관절에 입력되는 힘을 조정하여 다시 시도한다. 이 과정을 반복하면서 학습을 하는 것이다. 결국, 로봇은 수십번의 실패 이후 팬케이크 뒤집기에 성공한다.
무한의 탑 AI 강화 학습도 이와 같은 방식이다. NPC 간 1:1 대결에서 승리하는 것이 목표인 이 AI는 50여 개의 스킬 중 현재 상황에서 최적 스킬을 사용하도록 행동 한다. 장기적으로는 게임에서 이기는 것이 목표이며 단기적으로는 상대의 체력을 감소시키는 것을 피드백으로 줘 반복 학습시키는 것이다. 최소한 10만 번 정도 반복한다. 이를 통해 점진적으로 개선 시켜나갈 수 있다.
좀 더 자세히 이야기하자면 아무 데이터도 입력되지 않은 AI에게 스파링 파트너로 AI를 붙여서 AI들끼리 비무를 하게 한다. 그러면 파트너 AI와 직접 플레이하는 과정에서 AI가 상황마다 써야 할 스킬들을 사용하면서 비무를 익힌다.
AI는 3가지 단계의 강화 학습 과정을 밟는다. 물론 이 내용은 '이런 개념이다' 정도의 설명으로 자세한 내용은 논문 등을 통해 알아가는 것이 좋다.
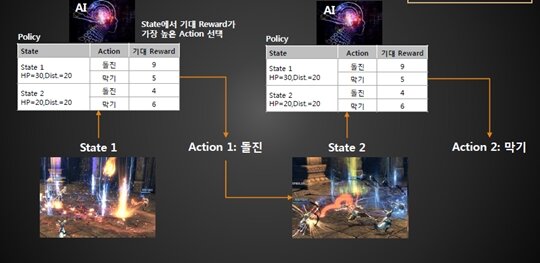
우선 AI vs AI로 대결 시뮬레이션을 돌린다. AI는 현재 상황(State)에서 기대 보상(Reward)가 가장 높은 행동(Action)을 취한다. 이것이 AI의 실체다. 아주 간략화한 테이블에 어떤 상황에서 어떤 액션을 취했을 때 기대 보상이 어떨 것이라는 AI의 판단이 서면 AI는 이를 그대로 행한다.
이런 반복되는 행동에 대해 로그를 수집하고 리플레이 스토리지(Replay Storage)에 저장하고 이를 바탕으로 보상을 조정하여 AI에게 학습을 시킬 수 있고 성능을 개선 시킬 수 있다.
특정 액션을 테이블에 근거하여 취했는데 자신의 피가 깎이면 부정적(Negative) 보상이 상승하고 상대의 피가 깎이면 좋은 상황이라고 인식하게 해 긍정적(Positive) 보상이 상승한다. 이러한 데이터가 쌓이면 AI는 테이블 자체를 바꾸고 이 과정을 계속 반복한다.
이러한 강화 학습에는 대단히 많은 기술이 포함되며 현재 상황이나 보상 설계(Reward Design)를 어떻게 할 것인가에 대해 많은 경험과 노하우가 필요하다.
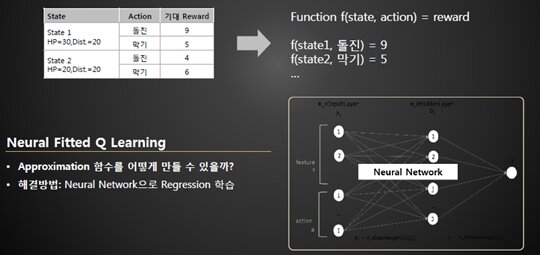
그러나 실제 게임은 이렇게 단순하지 않다. 실제 게임은 현재 상황에 대한 수가 너무 많아서 테이블 형태로 만드는 것이 불가능하다. 그래서 테이블을 유지하는 대신 근사치(approximation) 함수를 만들어야 한다. 이 함수는 뉴럴 네트워크(Neural Network)로 회귀분석(Regression)하여 해결 할 수 있다.
강화 학습에서 가장 중요한 것은 AI에게 다양한 경험 데이터를 만들어 주는 것이다. 간단한 규칙으로 만들어진 스파링 파트너 AI와의 대전만으로는 한계가 있기 때문이다. 또한, AI간 대결의 결괏값은 사람 vs AI의 결괏값과 같지 않다. 실제 라이브 서비스는 사람과 AI가 대결을 펼치는 콘텐츠이므로 차이가 나는 결괏값에서 유의미한 데이터를 찾기는 힘들다.
그래서 엔씨소프트 게임 AI팀은 주기적으로 플래티넘 급 유저를 데려와 AI와 대결을 펼치는 휴먼 플레이 테스트(Human Play Test)를 진행했다. 처음 테스트는 놀라웠다. AI가 무차별 공격을 하는 것 처럼 보였으나 유저는 빈틈을 이용해 유유히 빠져나와 한 콤보에 AI를 눕혀버렸다.
엔씨소프트 게임 AI팀은 문제를 파악했다. 일단 AI는 이기는 것이 목표이기 때문에 유리할 때도 방어를 하는 방향으로 학습이 됐다. 이를 수정하기 위해 전투 시간이 길어지면 페널티를 주는 방식으로 리워드를 줬다. 또한, 상대방이 상태 이상 상태에 빠졌는데도 불구하고 연계기를 사용하지 않는 것을 발견했다. 이 역시 시행착오를 겪으며 수정했다.
일반적으로 유저들은 스킬 셋을 한 번 읽고나면 어떻게 조합하겠다는 판단을 세운다. 하지만 AI는 그런 능력이 없어서 강화 학습 과정을 매우 반복해야만 했다. 이 AI는 테스트 3개월이 지나서야 겨우 한 번 승리할 수 있었다. 이경종 팀장은 사람의 능력은 경이롭다는 사실을 깨달았다.
매우 많은 반복과 시도 반복과 시도를 6개월쯤 했을 때 AI의 학습상태가 어느 정도 쓸만해 졌다. AI 역사와 유저 역사가 대결을 펼쳤는데 유저의 강력한 스킬을 저항기로 방어한다든지, 강력한 상태 이상을 걸고 연계를 통해 전세를 뒤집는다든지, 기회가 오자 스킬 콤보로 인간을 제압하는 모습을 보여줬다. 이 정도쯤 AI가 학습되자 엔씨소프트 게임 AI팀은 어느 정도 사람과 싸울 수 있다는 확신이 생겼다.
⊙ 강화학습시스템
이처럼 강화 학습을 하려면 무엇을 만들어야 할까. 구글 강화 학습 시스템 구조(Gorila, Google Reinforcement Learning Architecture)에서 핵심 요소(Component)는 환경(Environment), 수행자(Actor), 학습자(Learner)다.
'블레이드 & 소울' 무한의 탑 AI는 3개의 서버군으로 구성되어 있다. 게임이 진행되면 현재 상황에 대한 정보를 게임 서버가 AI 서버에 전달해준다. Actor에 해당하는 AI 서버에는 AI 에이전트가 올라가 있어 적합한 액션 및 스킬을 사용할 수 있도록 게임 서버로 전달한다.
이 과정은 전부 로그로 남는데. 이 로그는 Learner에 해당하는 러닝 서버로 보내져 계속 학습하며 네트워크를 갱신하고 갱신된 내용을 다시 AI 서버로 전달한다. 이 데이터는 트레이너(Trainer) AI 에이전트와 트레이니(Trainee) AI 에이전트를 업데이트한다.
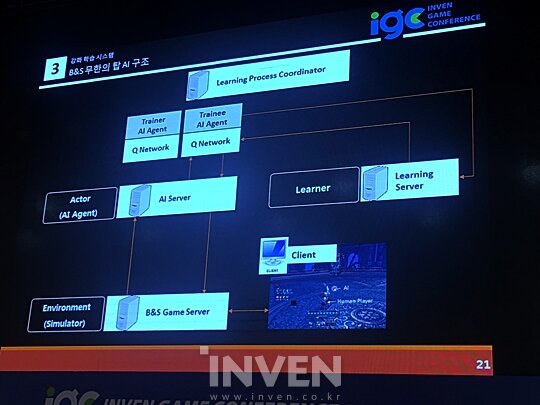
앞서 언급했듯 학습은 10만 번 이상의 반복을 통해 이뤄진다. 이처럼 대규모 시뮬레이션은 물리적으로 제약이 따른다. '블레이드 & 소울'의 대결 시간은 약 2분 정도인데 이를 10만 번하려면 대단히 많은 시간이 필요하나, 현실적으로 개발 시간은 이를 보장해주지 못한다.
그래서 엔씨소프트 게임 AI팀은 처음에 서버의 시간을 빨리 돌리는 방법을 생각했다. 그러나 라이브 서비스 중인 서버라 구현 위험성이 있었기 때문에 다른 방법을 탐색했다. 그들이 선택한 방법은 별도의 인스턴스 존을 만들어 반복하는 것이었다. 대단히 많은 인스턴스 존을 생성하여 AI 짝(트레이너, 트레이니)를 집어넣고 동시에 많은 값을 획득하는 방법이었다. 이를 통해 얻은 학습용 전투 로그를 러닝 서버에 보내 AI 에이전트를 업데이트했다.

이렇게 AI를 학습시키는 방법과 시스템을 마련한 이후에도 '무한의 탑'을 공식 서비스하기 까지는 큰 산이 남아있었다. 퍼포먼스(Performance)였다. 실시간으로 수많은 액션이 오가야 하는 게임의 특성상 요구 퍼포먼스는 (Performance Requirement) 1결정 당 (Decision)당 1 msec 미만이었는데 초기 버전은 10 msec을 넘어서고 있었다. 1 msec이면 트리서치(Tree Search)나 패스-파인딩(Path-Finding)은 엄두도 내지 못할 속도였다.
정보를 추출하는 과정(Information Extractor) 병목 현상(Bottleneck)이 발생하는 것이 원인이었다. 이를 해결하기 위해 코드와 구조 양 부문에 최적화를 진행했다. 소위 '이삭줍기'를 했다.
우선 코드를 최적화하기 위해 프로파일링 및 코드를 리뷰했다. 동시에 비주얼 스튜디오(Visual Studio) 모니터 툴을 활용했다. 구조적으로는 영역 지식(Domain Knowledge)을 적용해 불필요한 업데이트를 줄였으며 난이도 요소(Factor)를 연동하여 의사결정 횟수를 감소시켰다. 저 레벨 AI의 의사결정 틱(Decision Tick)을 2배로 증가시켰다. 반응 속도가 늦다는 것은 난도가 낮다는 것을 뜻하므로 의사결정을 덜 하면서 퍼포먼스를 좋게 끌고 나갈 수 있었다.
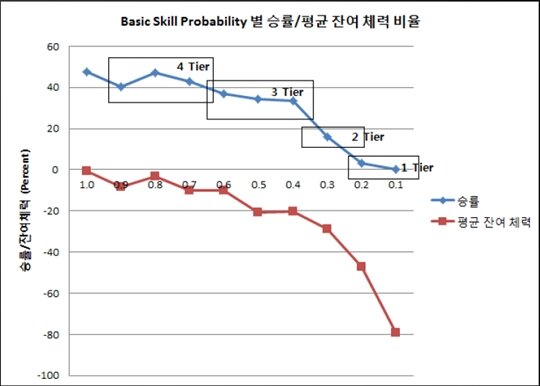
무한의 탑은 100층으로 구성되어 있고 층수가 올라갈수록 강력한 AI가 등장한다. 그래서 단계별 AI 난이도를 조절할 수 있는 요소(Factor)를 개발할 필요성이 있었다. 엔씨소프트 게임 AI팀은 이를 여러 종류의 스킬 노이즈(Noise) 등을 이용해서 조절했다.
공격과 방어 모두 별도의 팩터를 만들어서 하위 레벨에서는 방어 팩터를 낮췄다. 중요 스킬을 막거나 혹은 일부러 쉽게 반격할 수 있는 스킬을 사용해 일부러 당해주는 등 게임의 재미를 위한 기능 단위 난이도 팩터도 만들었다. 반응 속도 팩터는 여러 상황에 각기 다른 반응속도를 나타내도록 설정했다.
이후 직업별 최고의 AI를 만들어서 실험적으로 난이도를 결정해다. 난이도 팩터 조절을 통해 ELO 100점 정도에 해당하는 승률 35%가 차이 나도록 조정했다. 이 과정을 반복해 하위 레벨의 AI를 생성했다.
⊙ 향후 R&D 방향
무한의 탑에 사용한 AI는 MMORPG에 강화 학습 기반 NPC AI를 성공적으로 상용화했다는데 의의가 있다. 그러나 여전히 많은 숙제가 남아있다.
엔씨소프트 게임 AI팀은 이를 어떻게 해결해야 할지 고민 중이다. 강화학습을 통해 상용화에 성공할 정도의 AI를 만들었지만, 아직 최고 수준은 구현하지 못했다. 이경종 팀장은 '블레이드 & 소울' e스포츠계의 슈퍼스타인 김신경 선수를 한 번이라도 이길 수 있는 날이 오기를 소망하고 있다. AI 전투 성능을 향상해 최고레벨 플레이어 수준에 오르게 하는 것이다. 실제로 김신경 선수를 초빙해 AI와 대결을 한 적이 있는데 도대체 누가 기계인지 모를 정도로 압도적인 퍼포먼스 차이가 발생한 바 있다.
게임의 본질인 '재미'를 제대로 주기 위해 기계적인 반응을 완화한 사람 같은 AI(Human like AI) 개발과 실제 사용자 로그를 측정해 이를 어떻게 이용할지에 대해서도 고민 중이다. 또한 하나의 AI를 다른 장르에 적용할 수 있을지도 관심사다. 하나의 AI가 여러 장르에서 동작할 수 있을지 알아보는 것이다. 게임은 장르마다, 게임마다 완전히 다른 문제를 풀어야 하기에 통상 AI(General AI)를 일반적으로 사용할 수 없다.
엔씨소프트 게임 AI팀은 기계학습을 게임에 적용하는 데 있어 정수는 의사 결정 기술이라고 생각하고 있다. 강화 학습을 비롯하여 지능적 에이전트(Intelligent AI Agent), 지도 학습(Supervised Learning) 말이다.
이경종 팀장은 궁극적으로 재미있는 AI(Fun AI)를 추구하고 있다고 말했다. 정말 엄청나게 똑똑한 좋은 AI(Good AI)와 다르게 재미있는 AI는 티 안 나게 져 줄 수 있는 능력까지 지닌다. 일종의 충성 골프와 같다. 게임은 재미이고, 그러한 재미를 끌어내기 위해 극적인 게임을 만들 수 있게 하는 AI를 목표로 삼고 있다.


