
[유나이트 서울 2018 발표자 소개] 마완 매터(Marwan Mattar) 박사는 유니티의 엔지니어링 매니저로서 ML에이전트 프로젝트를 관리하고 있다. 그는 EA의 인텔리전트 시스템 그룹에서 기술 책임자로 머신 러닝을 통해 개인화된 플레이어 환경을 지원하기 위한 플랫폼을 설계하고 구축하는데 기여한 바 있다.
게임 속의 AI를 만들 때 지금까지 개발자들은 각 AI가 어떤 상황에서 어떻게 행동할지를 직접 코드를 작성해 구현해냈다. 지난해 9월 유니티는 인공지능 프로그램 및 앱을 개발할 수 있는 소프트웨어 개발 키트 ‘ML에이전트’를 공개했다. ML에이전트는 기존의 룰 코딩에 기반한 AI가 아니라 머신 러닝을 통해 AI를 가르칠수 있도록 하며, 이를 통해 개발 시간을 단축하고 보다 사람과 흡사한 행동을 하는 AI를 구현해낼 수 있다.
금일(3일) ‘유나이트 서울 2018’에서 마완 매터 엔지니어링 매니저는 강연을 통해 ML에이전트의 개념과 어떻게 AI에게 행동을 트레이닝할 수 있는지를 설명하고 직접 시연을 통해 각 기능을 확인해보는 시간을 가졌다. 강연에서는 기초적인 설명에 이어 직접 ML에이전트를 통해 지능형 행동을 트레이닝하는 과정을 직접 시연하는 섹션으로 구성되어있었으며, 프로그램에 대한 소개도 이루어졌다.
한편, 유니티의 ML에이전트 베타 버전은 오픈 소스 소프트웨어로 공개되어있어 바로 다운받아서 실행해볼 수 있으며, 각 단계에 대한 설명과 참고가 될만한 예시, 기초적인 알고리즘도 포함되어있다.
■ ML에이전트 - 게임 세팅, 트레이닝, 게임 적용까지의 세가지 단계

먼저 마완 매터 매니저는 ML에이전트에서 각 플러그인이 어떻게 구현되는지를 네 가지 예시를 통해 소개했다. 첫 번째 예시에서는 공이 플랫폼 위에 놓여있고, 이를 떨어트리지 않는 것이 목적이다. 플랫폼은 12개로, 각각 하나의 에이전트가 부여되어있다.
두 번째 예시에서는 파란색 큐브가 캐릭터로, 행동하는 주체다. 큐브의 행동은 벽으로 다가가 벽을 넘는 것으로, 벽이 어느 정도 높이냐에 따라서 점프할 수 있도록 박스를 벽으로 밀어서 점프를 하는 식으로 행동을 하도록 설정되어있다. 벽이라는 변수를 배우느냐가 관건인 사례다.

세번째 예시에서는 복합적인 행동이 요구된다. 캐릭터인 파란색 큐브는 앞에 놓여있는 큐브의 색을 인지하고, 이를 기억해서 알맞은 색의 구역으로 나아가야 한다. 캐릭터는 색을 기억하는 메모리를 가진다.
네번째 예시에서는 2개의 행동이 들어간다. 간단한 축구가 구현되어있음을 알 수 있으며, 골키퍼와 스트라이커로 나누어져 각각 캐릭터에게 보상을 주어 게임을 하면서 보상을 주는 방법으로 트레이닝 됐다.
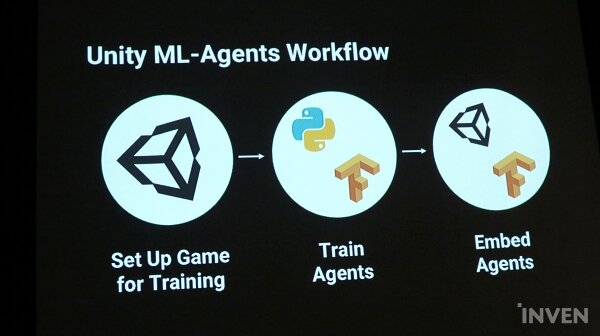
ML에이전트로 AI를 트레이닝하고 게임에 구현하는 데에는 크게 세 가지 단계를 거치게 된다. 게임을 셋업하고, 에이전트를 트레이닝하며, 이를 게임에 임배딩하는 단계로 구성되어있다.
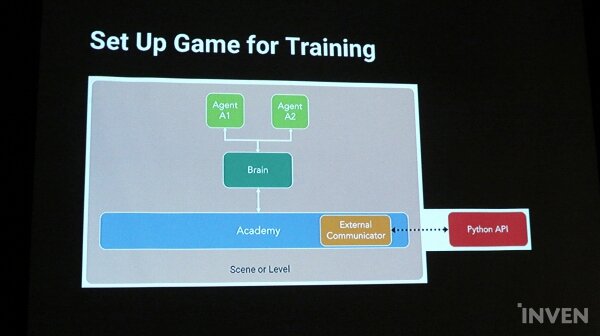
먼저 게임 셋업 단계다. 게임 셋업에서는 먼저 유니티 Scene을 만들면서 시작된다. 이에 유니티 스크립트를 전체적으로 관리하게 되는 아카데미를 생성하게 되며, 그 안에 각각의 에이전트의 행동을 조정하게 되는 브레인이 포함된다. 브레인은 에이전트가 어떤 행동을 할지 옵저베이션을 통해 결정하고 통제한다. 예를 들어, 플랫폼 위의 공의 경우 에이전트가 하나씩 12개로, 행동하는 실제 캐릭터인 에이전트가 하나의 브레인에 연결되게 된다. 브레인은 이런 상황에서는 어떻게 할지, 무엇이 등장했을 때는 어떤 행동을 보여야 할지를 결정하는 역할을 한다.

브레인은 External, Internal, Player, 그리고 Heuristic의 네가지 모드로 나누어진다. External 브레인의 경우 아카데미에서 External 커뮤니케이터로 수집되어 파이썬(Python) API를 통해 선택한 라이브러리에 전달된다. Internal 브레인은 훈련된 모델을 만들어 게임에 실현하게 되며, Player은 플레이어의 입력을 통해 행동을 결정하고 Heuristic 브레인은 직접 코딩한 동작을 기반으로 행동을 결정한다.
■ 트레이닝의 두 가지 방법, 강화와 모방

에이전트 트레이닝은 두 가지 방법으로 이루어진다. 구체적으로 어떻게 트레이닝할지 정해 진행되는 강화 학습(Reinforcement Learning)과 액션을 보여주고 따라 하도록 만드는 모방 학습(Imitation Learning)이다.
강화 학습은 에이전트가 환경에 대해서 어떤 정보를 볼 수 있고, 어떻게 판단할지를 정해서 훈련된다. 에이전트는 특정행동을 했을 때 보상이 주어지며, 보상이 없더라도 성공과 실패에 따른 긍정적인, 부정적인 반응을 보여주면 된다. 컴포넌트를 정하고 수백만 번의 시뮬레이션을 통해 진행되며 에이전트는 각 턴마다 액션에 대한 확률을 결정하게 된다. 시뮬레이션을 통해 얻은 경험을 통해 에이전트는 액션에 대한 확률 매핑인 Policy를 수정하게 된다. 에이전트는 보상 또는 긍정적인 결과를 최대한으로 하기 위해 액션 확률을 수정하게 되면서 트레이닝된다.

모방 학습은 직접 플레이어가 어떻게 행동할지를 가르쳐 주는 방식으로 진행된다. 플레이어가 직접 조종해 가르칠 행동을 보여주는 티쳐 브레인(Teacher Brain)과 학습을 배우는 스튜던트 브레인(Student Brain)으로 나누어져 있다. 행동을 보고, 액션을 따라 하는 단순한 구조로 되어있다.
행동이 포함된 모델 파일이 만들어지면 이를 유니티에 임배딩하게 된다.

한편, 유니티 ML에이전트는 오픈 소스 소프트웨어로, GitHub에서 트레이닝 시나리오나 기능에 대해서 자세하게 알아볼 수 있으며, 유니티 및 머신 러닝에 대한 배경지식이 공유되어있어 비전문가 또한 쉽게 이용할 수 있게 되어있다. 또한, 단계별로 가이드를 제공하고 있어서 확인해 볼 수 있다. 특히, Optimal Hyper-Parameters를 통해 어떻게 최적화된 트레이닝을 할 수 있는지 알아볼 수 있도록 트레이닝 알고리즘을 제공하고 있다.
■ 강화 학습과 모방 학습을 통한 AI 트레이닝
이어 마완 매터 엔지니어링 매니저는 직접 ML에이전트를 통해 에이전트들을 강화 및 모방 학습으로 트레이닝하고 유니티로 가져와 게임에 적용하는 단계를 시연을 통해 소개했다.
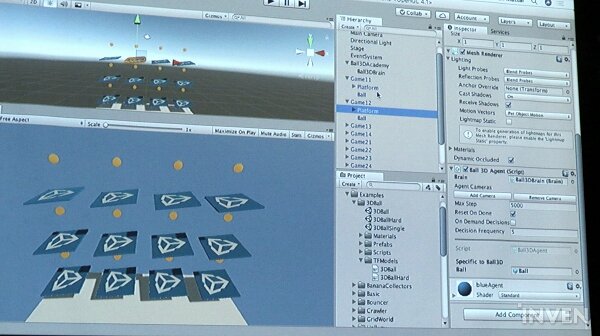
강화 학습에서는 직접 행동에 대한 조건을 설정해 트레이닝하게 된다. 마완 매터 매니저는 플랫폼에 올려진 공을 떨어트리지 않는 사례를 통해 강화 학습 과정을 설명했다. 이 예시에서는 브레인의 8개의 옵저베이션을 통해 에이전트의 행동에 대한 조건을 설정되었으며, 플랫폼과 볼 사이의 높이나 거리 등이 설정된다. 마완 매터 매니저는 옵저베이션을 지정할 때, 과학이라기보다는 아트라고 생각하고 설정해야 한다고 설명했다.
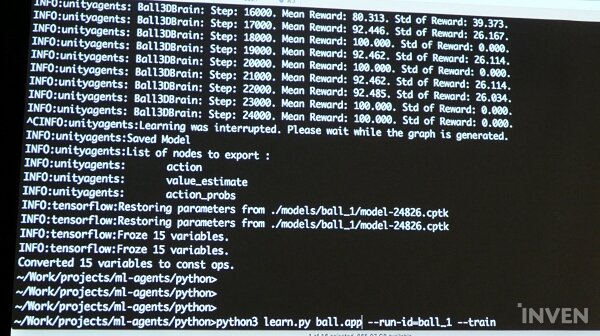
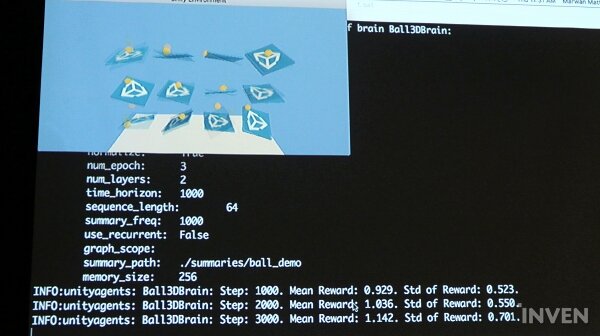
시뮬레이션의 매 회차마다 보상 값이 올라가는 것을 볼 수 있으며, 이에 따라 공을 빠르게 떨어트렸던 플랫폼이 점차 공을 떨어트리지 않고 유지해나가는 모습을 확인할 수 있다. 터미널에서는 각 에피소드와 섹션에서 에이전트가 어떤 것을 달성한 것을 확인할 수 있으며, 리워드가 100에 도달하면 트레이닝이 끝난다. AgentReset은 에피소드마다 공이 떨어져 액션이 완료되었을 때, 공을 플랫폼 위의 랜덤한 장소에 올려두는 것을 의미한다. 매 턴마다 다른 위치에 올려둠으로써 에이전트가 다양한 가능성에 대해서 학습할 수 있도록 한다.
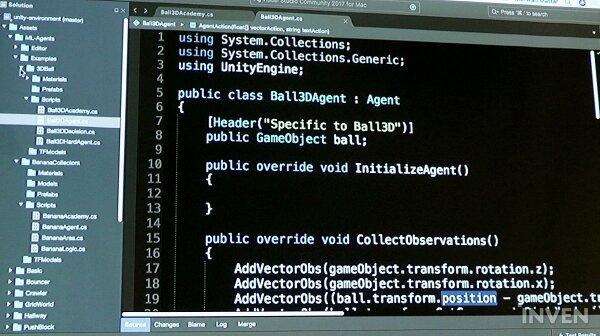
여기서는 에이전트의 로테이션 중 Y축은 상관이 없어서 빠져있는 것을 확인할 수 있다.
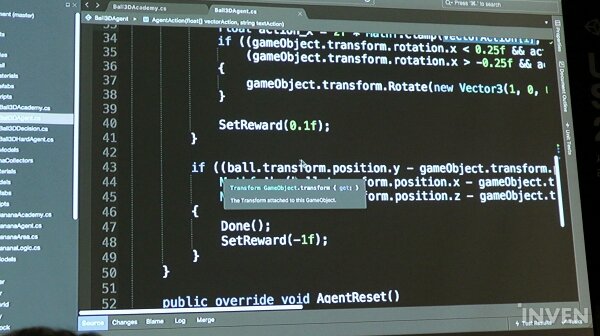
Done부분은 볼이 떨어져 액션이 완료된 상황이며, 에이전트가 실패했다고 간주하게 된다.
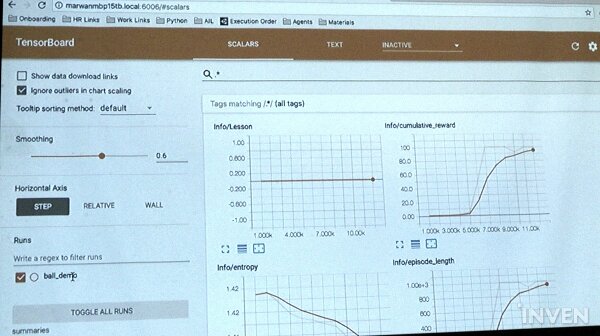
Tenser board에서는 트레이닝 프로세스에 대한 통계를 시각화해서 보여준다. 데모를 했던 정보를 확인할 수 있으며, 필터링도 가능하다. 통계를 통해 트레이닝 프로세스가 어떻게 진행되었는지를 확인하고 반복을 통해 더 나은 값을 가져갔는지 체크해 볼 수 있다. 얼마만큼의 리워드를 에이전트가 축적했는지 확인하고 원한 액션의 목표 값이 상승 곡선을 그리고 있는지를 확인한다.
반복 학습은 브레인이 두 개 설정된다. 플레이어가 조작해 직접 가이드를 하게 되는 티쳐 브레인과 이를 배우는 스튜던트 브레인이다. 플레이어는 에이전트를 움직여 액션을 보여주고, 에이전트는 이를 보고 따라 하게 되며, 빠르게 학습하고 있는 것을 확인할 수 있다.
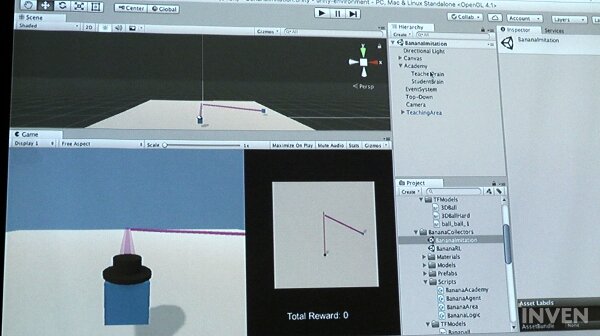

티처 브레인에 연결된 에이전트를 움직여 빙글빙글 돌면 다른 스튜던트 브레인에 연결된 에이전트들이 따라서 도는 것을 확인할 수 있으며, 노란색 바나나만을 찾아 획득하는 행동을 보이면 따라하는 것을 확인할 수 있었다.
