
게임의 흥망성쇠를 좌우하는 유저들은 어떤 유저일까요. 게임의 유저군은 다양합니다. 짧고 굵게 즐기는 유저가 있는가 하면, 라이트하게 즐기는 유저들도 있고 남들과는 다른 재미를 추구하는 유저도 있습니다. 이른바 게임의 흥망성쇠를 좌우하는 유저들을 진성 유저라고 하는데요. 이런 유저들은 오랜 시간 게임을 즐기면서 고과금을 하기에 개발사로서는 예의주시할 수밖에 없습니다.
그렇다면 개발사는 여러 유저군을 어떻게 살펴볼까요. 보통 개발사에서는 AU(Active Users)를 통해 유저들의 지표를 살펴보곤 합니다. 하지만 이걸로는 여러 유형의 유저군들을 나눌 수는 없습니다. 개발사가 원하는 진성 유저와 같은 특정 유저를 분석하기 위해선 더 발전된 지표가 필요한데요.
좀 더 명확한 진성 유저를 파악하기 위해, 데이터마이닝으로 진성 유저 지표를 만들었다는 엔씨소프트의 엄혜민 강연자. 그녀가 만든 진성 유저 지표에 대한 일련의 작업 과정을 지금 소개합니다.

■ 진성 유저 지표를 만들게 된 이유는?
온라인 게임의 경우 다양한 유저들이 한 공간에 모여서 플레이를 하고, 이벤트나 업데이트를 통해 계속 변화하는 세계를 갖고 있습니다. 즉, 매번 변화하는 온라인 게임에서는 플레이하는 유저들의 동향을 파악하는 게 무엇보다도 중요한데요. 그중에서도 게임의 흥망성쇠를 좌우하는 유저, 이른바 진성 유저를 파악하는 게 핵심이었습니다.
그런데 진성 유저를 파악하는데 있어서 우선 어떤 유저군이 진성 유저인지 구분할 필요가 있었습니다. 제가 주변 분들과 의논을 하니 어떤 분은 게임을 엄청나게 즐기는 골수 유저를, 또 어떤 분은 매출 등을 높이는 고과금 유저를 진성 유저라고 생각했습니다. 그래서 저는 우선 진성 유저에 대한 구분을 짓고자, 로그를 통해 어떤 유저들이 있는지부터 파악했습니다. 데이터마이닝을 통한 탐사, 분석을 시작한 거였죠.

■ K-means 클러스터링 기법으로 유저 유형 분류

우선 유저 유형을 파악하는데 있어서는, K-means 클러스터링 기법을 사용했습니다. 이 기법은 데이터 비교를 통해 유사한 유형들을 모아서 하나의 클러스터(군집)로 묶는 방법인데요. 데이터를 이용해 자신이 원하는 수만큼의 유저군을 나눌 수 있습니다. 물론, 클러스터링을 하면서 유저군을 나누기 위해서는 피쳐(Feature, 유저를 설명해주는 데이터)를 선정할 필요가 있습니다. 보통은 플레이 타임, 사냥 횟수, 경제 활동 등을 피쳐로 등록합니다.
그런데 유저군을 나누는 데 있어서 그 수를 조절할 필요가 있습니다. 예를 들어 유저군을 다양하게 할 경우, 세분화된 유저 데이터를 얻을 수 있지만, 그 수가 너무 많을 경우에는 특정 유저군을 파악하기 어렵다는 단점이 있습니다. 반대로 적으면, 큰 틀에서 유저 유형을 나눌 수는 있지만, 다양한 유형들이 통합될 수 있다는 각각의 장단점이 있죠.
저희는 우선 유저군을 5개로 나눠서 파악했습니다. 그 결과 1번 유저군은 다양한 콘텐츠에 대한 높은 사용량을 보이는 부류, 2번 유저군은 다양한 피쳐에서 중반 정도의 고른 수치를 보이는 부류, 3번은 전반적인 컨텐츠 이용률이 낮은 부류 등으로 나눌 수 있었습니다.
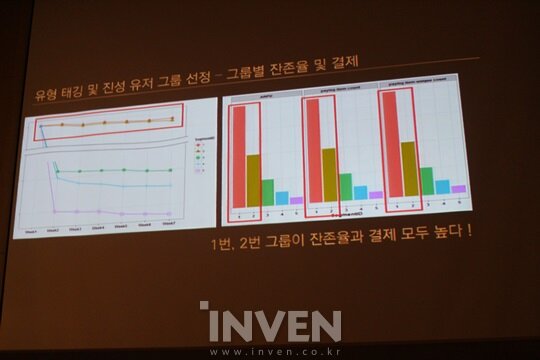

저희는 이 부류를 1번은 열성형, 2번은 일반형, 3번은 라이트형, 4번은 골드 파밍형, 5번은 체리 피커형이라고 불렀는데요. 이 수치를 통해 1번과 2번 유저군이 우리 게임의 진성 유저군에 가깝다는 걸 파악할 수 있었습니다.
이렇듯 만족스러운 지표를 얻었지만, 문제는 매번 로그를 통해서 데이터를 얻고 그걸로 다시 지표를 파악하고 하자니 너무 능률이 떨어진다는 거였습니다. 그래서 저희는 지표 생성을 자동화하기로 했습니다.
■ 수동으로 지표를 분석하긴 힘들다. 지표 생성 자동화를 하자
지표 생성을 자동화하기에 앞서 새로운 기법을 사용할 필요성이 있었습니다. K-means 클러스터링 기법의 경우, 매번 유저들의 데이터를 수동으로 작업해야 하는 부분이 있었거든요. 그래서 저희는 랜덤 포레스트(Random Forest) 기법을 도입했습니다.
랜덤 포레스트는 여러 개의 디시전 트리(Decision Tree)를 융합하여 사용하는 분류 알고리즘으로 높은 정확도 대비 낮은 과적합으로 안정적인 성능을 보장했습니다. 디시전 트리는 다양한 정보를 통해서 예측할 수 있는데요. 여러 개의 디시전 트리를 사용하면 더 정확한 예측을 할 수가 있습니다.


랜덤 포레스트 기법을 통해 이제 더 정확한 진성 유저 지표를 얻을 수 있게 됐습니다. 하지만 지표를 놔두기만 하면 안 되죠. 바로 이 지표를 활용해야 합니다. 앞서 지표에 대해 설명할 때 AU가 올랐다가 바로 떨어진 사례가 있었습니다. 이걸 예측 모델로 파악하면 당시에 체리 피커형 유저들이 게임을 즐기다가 접었다는 걸 파악할 수 있습니다.
■ 변동성이 큰 지표들, 지표 기준선이 필요하다
지표 분석을 통해 이제는 여러 정보를 얻을 수 있지만, 이 방법도 완벽하진 않습니다. 프로모션과 이벤트 등 AU에 영향을 미치는 요인들이 있기 때문입니다. 그렇다면 어떻게 해야 할까요. 외부 요인들이 지표에 어떻게 영향을 미치는지 파악하기 위해서는 지표 기준선을 만들 필요가 있죠.
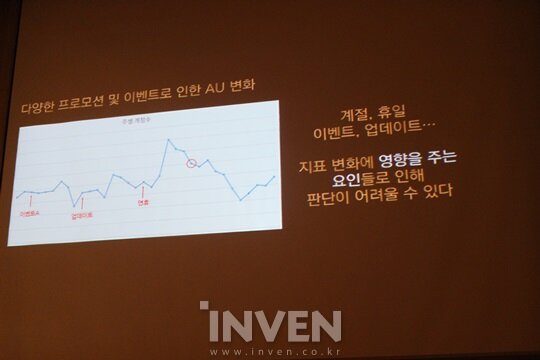
지표 기준선을 만들기 위해서는 회귀 분석 기법을 이용했습니다. 이 기법은 한 종속변수가 다른 독립 변수들에 의해서 어떻게 예측되는지 알아보기 위한 통계적 방법인데요. 지표 기준선이 마련된다면 복잡한 지표 속에서 지표 기준선을 찾고, 프로모션이나 이벤트 등의 영향도를 파악할 수 있게 됩니다. 자, 이걸로 이제 다양한 지표들을 파악할 수 있게 됐습니다. 유저군을 나눌 수 있고, 자동화하고 프로모션이나 이벤트 등의 영향력까지 확인할 수 있게 됐습니다.
■ 이제는 지표를 활용할 때
자, 이제 정리하도록 하겠습니다. 기존의 AU 지표에서 좀 더 나아간 유형별 유저 동향을 파악할 수 있다면, 현재 게임 세계의 흐름을 더욱 명확하게 감지할 수 있습니다. 지표 기준선을 정하면 외부 영향 역시도 파악할 수 있죠. 실제로 데이터만 준비된다면 이 작업은 큰 어려움도 없습니다. 끝으로 말하겠습니다. 이제는 지표를 활용할 때입니다.


