








검은사막 화제집중
- 리포터 뉴스
- 실시간 유저뉴스
- 아이템 자랑하기
- └ 강화 후기 게시판
- 관리자 인증 게시물
- 팁과 노하우
- └ 신규/복귀자용 팁 모음
- └ 지식 정보 모음
- 용병, 파티모집/쿠폰
- 생활 종합 게시판
- 탈것 정보 공유 게시판
- 제작 레시피/재료 공유
- 바란다/버그 제보
커뮤니티 게시판
미디어 게시판
서버 게시판
직업 게시판
공통 커뮤니티
- 오픈 이슈 갤러리
- 오늘의 핫벤
- 오늘의 팟벤
- AI 그림 그리기
- PC 견적 게시판
- 코스프레 갤러리
- (19)무인도는 첨이지?
- 게이밍 주변기기
- 지름/개봉 갤러리
- 게이머 토론장
- 게임 추천/소감
- 무엇이든 물어보세요
- 최근 논란중인 이야기
- 더보기
인기 팟벤

|
2023-10-02 22:47
조회: 10,943
추천: 16
수많은 실험글들을 위하여확률에 대하여
우리가 게임을 하다 보면 항상 갖는 의문이 있음. 내가 이 장비를 강화할 때 확률이, 혹은 아이템을 파밍할 때 드롭률이 정말 맞는 확률일까? 이를 검증하기 위해서 수많은 유저들이 수많은 장비를 깍고 수많은 몬스터를 잡고 있음. 그럼 나의 노력들이 신뢰성을 가지려면 얼마만큼의 시행횟수를 채워야 하는가?에 대해서 논하고자 함.
테스트 수가 많으면 많을수록 정확한 확률이 나올거라는 기대는 다들 직감적으로 알고 있을거임. 쉽게 말하면 샘플 수가 많으면 많을수록 테스트 결과를 신뢰 할 수 있음. 그러나 1000번 잡아서 12번 나왔다고 아이템의 획득확률이 1.2%라고 하는 것은 시험자가 뽑은 표본의 확률이지 모집단(서버)의 확률이라고 보기는 어려움. 그럼 이걸 어떻게 통계적으로 설명할수 있을까?
용어 설명 겸 기초적인 설명 먼저함. 확률의 검정은 보통 귀무가설의 기각여부로 판단함. 귀무가설(Null hypothesis)은 보통 두 집단이 같다, 대립가설(alternative hypothesis)은 두 집단이 다르다로 놓고 비교하게 됨. 예를 들어, 게임에서 공시하는확률이 1%인데 내가 1천번의 시행을 통해서 1.2%의 확률이 나왔다면 이걸 거의 맞다고 봐야할까 아닐까? 대충t-test를 시행하면 일정 유의수준에서 공시확률과 내가 계산한 확률이 같은지 다른지 판단 할 수 있음. T-test는 프로그램만 쓰면 누구나 다 할 수 있는데 문제는 테스트를 얼마나 많이 해야하는지임.
유의수준이 무엇이냐하면, 통계에서 제 1종 오류가 나타날 확률을 말함. 쉽게 말해 귀무가설(공시확률과 테스트확률에 차이가 없다)이 참임에도 내가 이걸 틀리다고 판단하게 될 확률임. 분야에 따라 다르겠지만 보통 5%정도면 사회에서 통용되는 수준임. 제 2종 오류는 귀무가설이 거짓인데 내가 이걸 맞다고 판단하게 될 확률임. 2종 오류를 범하지 않고 올바른 결정을 내릴 확률이 검정력임. 검정력이 높을수록 공시확률과 내가 계산해본 확률이 다르다고 결론지을 수 있는 수준이 높아짐.
본론으로 들어가기에 앞서 프로그램 하나를 소개하고자 함. 대학원생들에게는 유용한 툴이니까꼭 참고하기 바람.
G Power (여러다양한 통계적 분석을 할 때 결과가 가지는 power, 검정력을 계산해주는 프로그램)
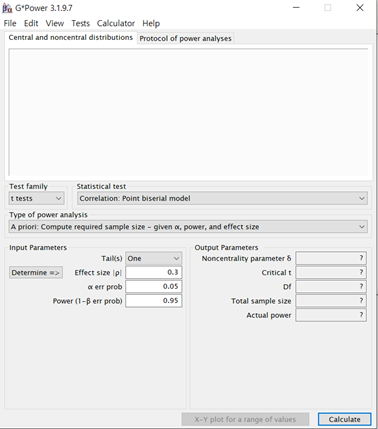
용어에 대한 설명은 넘어가고 예시로 보여줄까함. 이제부터 설명하는건 내가 얼마만큼의 샘플을 모아야 일정 레벨의 유의수준과 검정력으로 내가 시행하는 statistical test가 통계적으로 의미있다고 볼 수 있는지 알아보기 위한 pre-calculation이라고 보면 됨.
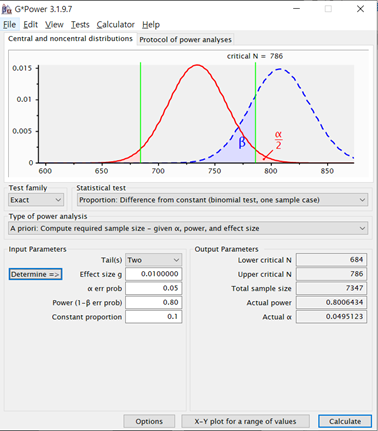
여기서 우리는 Test family = exact, Statistical test = Proportion: difference from constant(binomial test, one sample case), Type of power analysis = A priori: Compute requiredsample size – given a, power,and effect size 로 설정할거임. 그리고 Input Parameters에서 Determine을 클릭하면
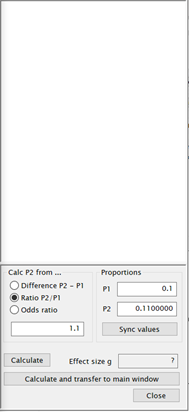
이런 화면이 나옴. 여기서 P1은 인게임 공시확률, P2에는 내가 계산한 확률을 넣으면 됨. 만약 드롭률이 10%인데 내가 한 시간동안 사냥해보니까 11%로계산됐어, 그러면 P1에 0.1,P2에 0.11을 넣으면 됨. Difference P2 – P1과 Ratio P2/P1 둘중 하나를 보통 선택 할텐데, 이걸 effect size라고함. 자세한 설명은 넘어감. Effect size에 대해서인용을 하나 하면, “표본수 계산과정에서 필요한 것은 단측/양측검정 여부, alpha error, beta error, 비교하려는 집단 사이의 예상 평균 차이, 예상 표준 편차이다. 이 중 단측/양측검정, alpha error와 beta error는 모두주어진 값이므로 실제 필요한 것은 예상 평균 차이와 예상 표준 편차뿐이다”라고 함. 즉, effect size는 예상 값이고 내가 설정하는 값임. 아무렇게나 설정하는건 아니고 내가 대충 한시간이면 한시간 사냥하고 나온 결과치로 입력하면 됨. 이 때는 pre-test라서 표본 수가 부족하기 때문에, P2 확률값을 입력하고나서최종 계산된 sample size를 기반으로 추가 실험을 진행하면 됨. 그 후 Calculate and transfer to main window를 누르면,
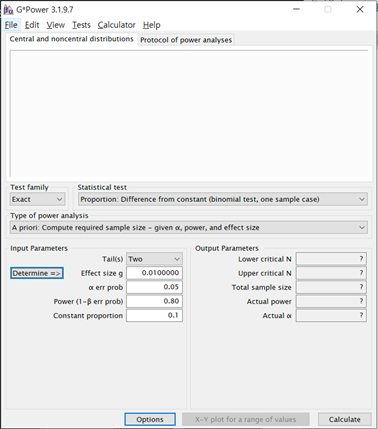
위 화면처럼 메인화면에 숫자가 적용되서 나옴. Effect size는 내가 계산한 확률과 공시확률의 차이 a err prob는 유의수준 Power (1- b err prob)는 검정력 Constant proportion은 공시확률
Input parameter에서 Tail은 one-tail과 two-tail이 있는데, 표본의 확률과 모집단의 확률이 다른지 확인하고 싶을 땐 two-tail, 공시확률보다 내가 설정한 확률이 높거나 낮거나, 둘 중 하나로 확실할 때는 one-tail로 하면 됨.
여기서 아래 Calculate를 누르면,
이렇게 나옴. 해석하면, 필요 샘플수는 7347개이고, 7347번 시행해서 684개보다적게 먹거나 786개보다 많이먹으면 유의수준 5%, 검정력80%로 봤을 때 통계적으로 공시확률의 신뢰성에 의문을 제기할 수 있음. 간단히 말하면 인게임 공시확률이 10%인데 내가 계산해보니 11%가 나오는데? 10퍼는 틀린거 아님? 이라고 주장하고 싶으면 7347번의 테스트를 하셈. 검정력을 90%로 높여서 내 주장의 오류를 낮추고 싶으면 9857번을 해야함. 혹은 1%차이까지 검증하는건 어렵고 공시확률이 10%인데내가 테스트 해본 확률이 20%일 때 두가지를 비교해보고 싶다면, 필요샘플 수는 94번만 하면 됨. 이런식으로 조절해가면서 필요 샘플 수를 찾아가면 됨.
재미로 엘텐확률이 실제보다 1/5수준으로 드랍률이 낮은지 검정해볼까? One-tail, Effect size -0.0000040, a err prob 0.05, Power (1- b err prob) 0.9로 계산 시 필요한 시행 횟수는 1,550,729가 나옴. 엘텐 155만마리 잡아야 됨 ㅋㅋ.
유의성이 높아지고, 검정력이 낮아지고, 확률간 차이(effect size)가 커질수록 필요한 테스트의 수는 기하급수적으로 떨어짐. 내가주장하고 싶은 통계적 수준에 맞춰서 실험을 진행하면 되겠음.
마지막으로 통계학에는 Rule of thumb 라는 유명한 문구가 있음. 아무래도 모르겠으면 일단 30회를 하셈. 그러면 대충 정규분포를 따른다고 가정하고 통계적인 의미를 가질 수 있는 최소한의 시행횟수를 얻을 수 있는거임.
끝.
*글 쓰면서 여러 번이나 ‘~를가정하고’, ‘~를 제외하고’ 따위를 썼다가 오히려 읽기힘들까봐 제외한 부분이 많으니 혹여 전공자가 보더라도 너그러이 봐주기 바람. 데없찐이라 음슴체로 썼음. 반박 시 귀찮으니까 안받음, 더 정확한 글이 있다면 새로 쓰셈 그럼본 글은 폭파하겠음. 인용 출처도 귀찮음. **통계가 만능은 아님. 제 1, 2종 오류가 있으니까. 그러나 최소한 뭔가 주장을 하려면 근거가 있어야 하는데 근거없이 주장하는 사람 혹은 반박하는 사람들을 위한 글임.
EXP
1,764
(82%)
/ 1,801
|

 줄리탄
줄리탄