
IT인벤 화제 집중
IT 커뮤니티
공통 커뮤니티
- 오픈 이슈 갤러리
- 오늘의 핫벤
- 오늘의 팟벤
- AI 그림 그리기
- PC 견적 게시판
- 코스프레 갤러리
- (19)무인도는 첨이지?
- 게이밍 주변기기
- 지름/개봉 갤러리
- 게이머 토론장
- 게임 추천/소감
- 무엇이든 물어보세요
- 최근 논란중인 이야기
- 더보기
인기 팟벤

|
2024-03-12 17:35
조회: 1,765
추천: 0
한국 연구자들은 새로운 신경 AI 칩으로 Nvidia를 부끄럽게 만들었습니다. 전력 소모량이 625배 적고, 41배 더 작다고 주장합니다.기사 원문 - https://www.tomshardware.com/tech-industry/artificial-intelligence/korean-researchers-power-shame-nvidia-with-new-neural-ai-chip-claim-625-times-less-power-41-times-smaller
 한국과학기술원(KAIST) 과학자팀은 최근 2024 국제고체회로회의(ISSCC)에서 '상보형 변압기' AI 칩을 자세히 설명했습니다. 새로운 C-Transformer 칩은 LLM(대형 언어 모델) 처리가 가능한 세계 최초의 초저전력 AI 가속기 칩이라고 합니다. 보도 자료 에서 연구원들은 C-Transformer가 그린 팀의 A100 Tensor Core GPU보다 625배 적은 전력을 사용하고 41배 더 작다고 주장하면서 Nvidia를 비난했습니다. 또한 삼성이 제조한 칩의 성과는 주로 정교한 뉴로모픽 컴퓨팅 기술에서 비롯된 것임을 보여줍니다. 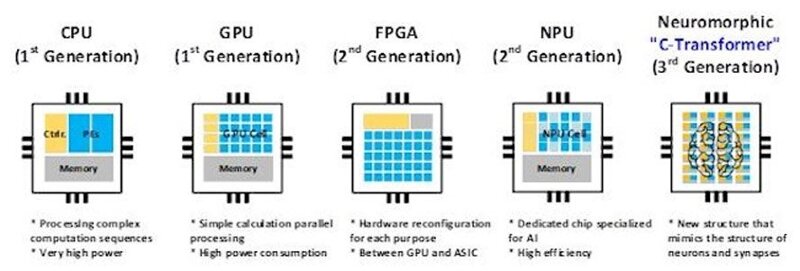 KAIST C-Transformer 칩이 Nvidia의 강력한 A100 GPU 중 하나와 동일한 LLM 처리 작업을 수행할 수 있다고 들었지만 , 언론이나 컨퍼런스 자료 중 어느 것도 직접적인 비교 성능 지표를 제공하지 않았습니다. 이는 중요한 통계이고, 그 부재로 인해 눈에 띄며, 냉소적인 사람은 아마도 성능 비교가 C-Transformer에 어떤 이점도 주지 않는다고 추측할 것입니다.  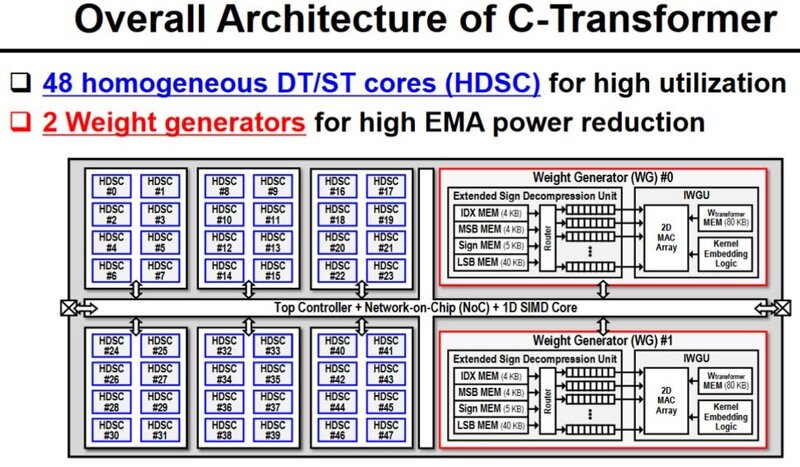 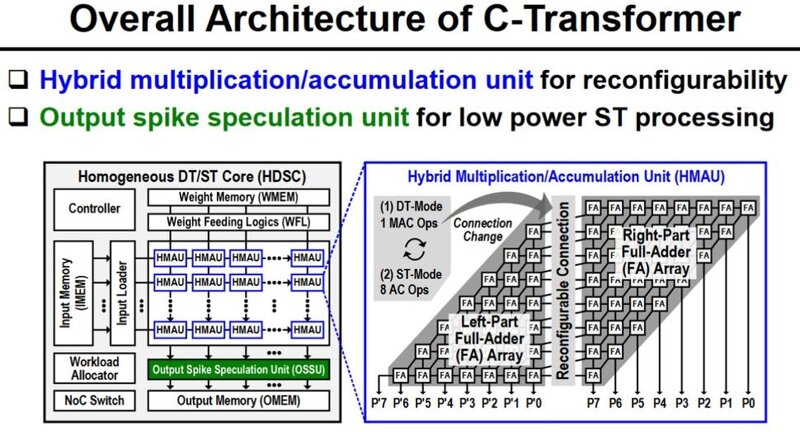  위 갤러리에는 '칩 사진'과 프로세서 사양 요약이 있습니다. C-Transformer는 현재 삼성의 28nm 공정으로 제작되었으며 다이 면적은 20.25mm2입니다. 최대 200MHz 주파수에서 작동하며 500mW 미만을 소비합니다. 기껏해야 3.41 TOPS를 달성할 수 있습니다. 액면 그대로, 이는 Nvidia A100 PCIe 카드의 624 TOPS보다 183배 느립니다(그러나 KAIST 칩은 625배 더 적은 전력을 사용한다고 주장됩니다). 그러나 우리는 각 플랫폼이 주장하는 TOPS를 살펴보는 것보다 일종의 벤치마크 성능 비교를 선호합니다. C-Transformer 칩의 아키텍처는 흥미롭고 세 가지 주요 기능 블록이 특징입니다. 첫째, 동적으로 변화하는 분배 에너지를 효율적으로 처리하기 위해 HMAU(Hybrid Multiplication-Accumulation Unit)를 갖춘 Homogeneous DNN-Transformer/Spiking-Transformer Core(HDSC)가 있습니다. 둘째, 스파이크 도메인 처리의 지연 시간과 계산을 줄이기 위한 출력 스파이크 추측 장치(OSSU)가 있습니다. 셋째, 연구원들은 EMA(외부 메모리 액세스) 에너지 소비를 줄이기 위해 확장 부호 압축(ESC)을 갖춘 IWGU(암시적 가중치 생성 장치)를 구현했습니다. C-Transformer 칩은 LLM의 큰 매개변수를 압축하기 위해 '특수 소스'로 일부 기성 뉴로모픽 처리를 추가하는 것이 아니라고 설명됩니다. 이전에는 뉴로모픽 컴퓨팅 기술이 LLM 과 함께 사용하기에 충분히 정확하지 않았다고 KAIST 보도 자료에서 밝혔습니다. 그러나 연구팀은 "[심층 신경망] DNN에 맞도록 기술의 정확도를 높이는 데 성공했다"고 밝혔습니다. 업계 표준 AI 가속기 와 직접적인 비교가 없기 때문에 이 첫 번째 C-Transformer 칩의 성능에 대한 불확실성이 있지만 모바일 컴퓨팅을 위한 매력적인 옵션이 될 것이라는 주장에 대해서는 이의를 제기하기 어렵습니다. 연구원들이 삼성 테스트 칩과 광범위한 GPT-2 테스트를 통해 여기까지 도달했다는 점도 고무적입니다.
EXP
98,439
(28%)
/ 102,001
|
 Bector
Bector 









